
var threads = Executors
.newVirtualThreadPerTaskExecutor()
var subtaskA = threads.submit(this::taskA);
var subtaskB = threads.submit(this::taskB);
var result = subtaskA.get() + subtaskB.get();Structured Concurrency
in Action
Before we get started
Before we get started
Structured Concurrency in Action
Virtual thread potential
A first step
Structured programming
Unstructured concurrency
Structured concurrency
Structured concurrency
In action
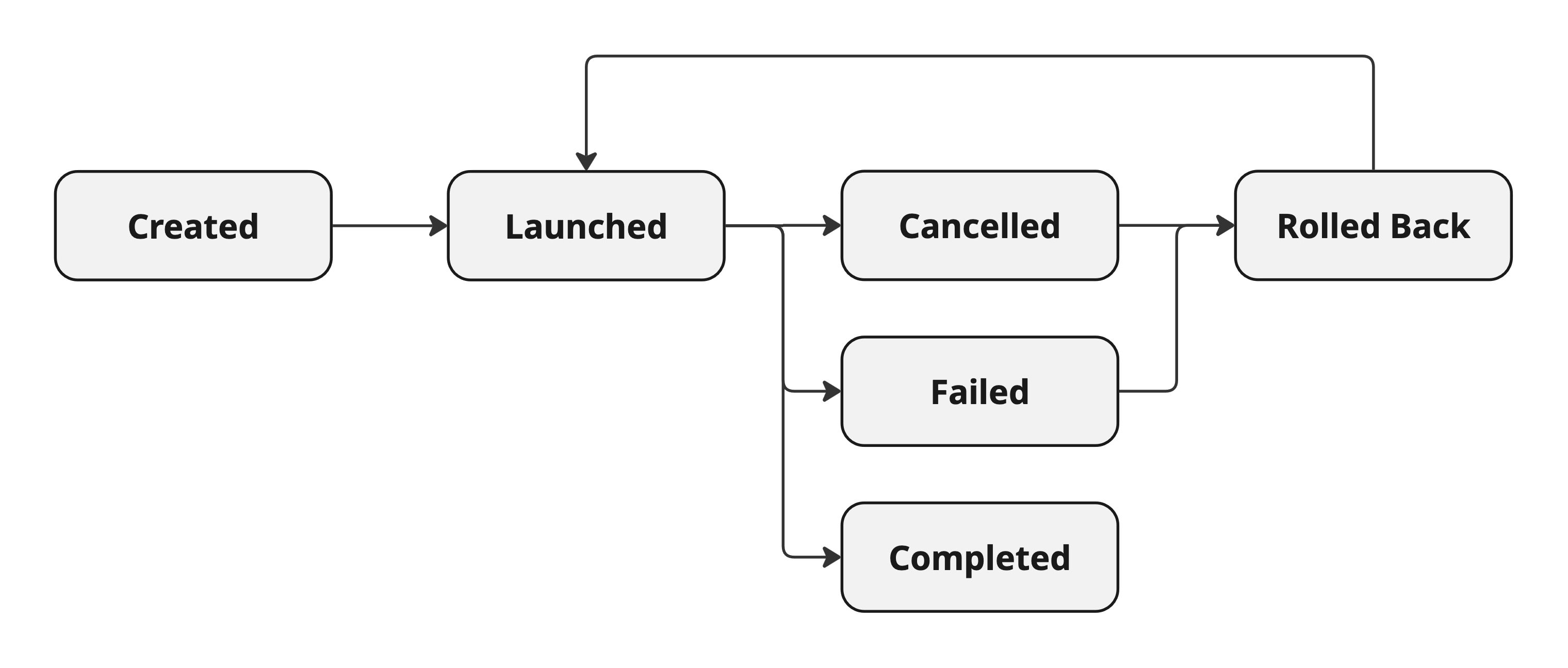
Task states
States and transitions of our tasks:
Code
Structured Concurrency in Action
Blocking methods
Interruption
Interruption API
InterruptedException
Cancellation
Code
Structured Concurrency in Action
Caveat
Backpressure
Between Operations
Between Threads
Between Processes
Backpressure Strategies
Code
Structured Concurrency in Action
Caveat
Reactive Streams
Reusable Operators
Code
So long…

More
Slides at slides.nipafx.dev⇜ Get my book!
Follow Nicolai
nipafx.dev/nipafx
Follow Java
inside.java // dev.java/java // /openjdk