
sealed interface Staff
permits Employee, Freelancer { }
final class Employee implements Staff { }
final class Freelancer implements Staff { }
// compile error
final class Consultant implements Staff { }Java 16 Is Coming!
Let’s get started!
this talk covers Java 16
and whatever else we have time forask questions any time or tweet at @nipafx
slides at slides.nipafx.dev/java-x
(hit "?" to get navigation help)they cover Java 9 to 16+ without module system
Lots to talk about!
| Language Changes |
| New and Updated APIs |
| New JVM Features |
| Performance Improvements |
New Language Features
| Sealed Classes |
| Records ⑯ |
| Pattern Matching ⑯ |
| Text Blocks ⑮ |
| Switch Expressions ⑭ |
| Local-Variable Type Inference ⑩ |
| All The Small Things... ⑨ |
New Language Features
| Sealed Classes |
| Records ⑯ |
| Pattern Matching ⑯ |
| Text Blocks ⑮ |
| Switch Expressions ⑭ |
| Local-Variable Type Inference ⑩ |
| All The Small Things... ⑨ |
Between final and open classes
Modeling A Domain
Many systems have central abstractions, e.g.:
staff/customers
delivery mechanisms
shapes
Commonly, polymorphism is used
to reuse code and attach functionality.
If many subsystems operate on abstractions,
there’s the risk of feature creep.
Modeling A Domain
Alternatively, subsystems can
implement their own handling.
Challenge is that subtypes
are effectively unknown, e.g.:
what subtypes of
Staffexist?what subtypes of
Shapeexist?
OO-solutions are cumbersome.
(e.g. visitor pattern)
Modeling A Closed Domain
In many cases, a type’s variations
are finite and known, e.g.:
Employee,FreelancerextendStaffCircle,RectangleextendShape
If subsystems rely on that,
their code becomes simpler (instanceof).
But less maintainable?
⇝ Only because compiler can’t help!
Compiler & Inheritance
There’s three options how a class can be extended:
by no classes (
finalclass)by package classes
(package-visible constructor)by all classes (
publicclass)
(For interfaces, there’s no choice at all.)
In all cases:
Implementations are unknown to the compiler.
Enter Sealed Types
With sealed types, we can express
limited extensibility:
only specific types can extend sealed type
those are known to developer and compiler
Sealed Staff
mark class/interface as
sealeduse
permitsto list types
Handling Sealed Staff
Goal is to combine sealed types,
switch expressions, and pattern matching:
public double cost(Staff staff) {
return switch(staff) {
// strawman syntax!
case Employee employee ->
employee.salary() * 2;
case Freelancer freelander ->
freelancer.averageInvoice() * 1.1;
// compiler checks exhaustiveness
}
}Handling Sealed Staff
But we’re not there yet.
For now:
sealed classes limit extensibility
(betweenfinaland non-final)prevent extension by users
express intention to maintainers
Sealing Details
There are a few details to discuss:
for the sealed type
for the premitted types
for both of those types
Sealed Type Details
Sealed types can extend/inherit as usual:
sealed class Staff
extends Person
implements Comparable<Staff>
permits Employee, Freelancer {
// ...
}Permitted Type Details
Permitted types must use exactly one of these modifiers:
finalfor no inheritancesealedfor limited inheritancenon-sealedfor unlimited inheritance
With sealed and non-sealed, a type
can admit further implementations.
Permitted Type Details
sealed interface Staff
permits Employee, Freelancer { }
non-sealed class Employee implements Staff { }
sealed class Freelancer implements Staff
permits Consultant { }
final class Consultant extends Freelancer { }But what about exhaustiveness?!
⇝ type pyramid has "exhaustive peak"
Permitted Type Details
Permitted types must directly extend sealed type:
sealed interface Staff
// compile error
permits Freelancer, Consultant { }
non-sealed class Freelancer implements Staff { }
class Consultant extends Freelancer { }This keeps type pyramid layered.
Permitting Records
Remember, records are implicitly final.
They make good permitted types.
Neighbours
Permitted types must be "close":
same package for non-modular JAR
same module for modular JAR
Sealed and each permitted type must be
visible/accesible to one another.
Flat Mates
If all types are in same source file,
permits can be omitted:
public class Employment {
sealed interface Staff { }
final class Employee implements Staff { }
final class Freelancer implements Staff { }
}Summary
Sealed types make inheritance:
more flexible between open and
finalanalyzable to the compiler
Consequences:
makes type tests more maintainable
(thanks to exhaustiveness checks).reduces need for complex OO solutions
(goodbye visitor pattern 👋)
New Language Features
| Sealed Classes |
| Records ⑯ |
| Pattern Matching ⑯ |
| Text Blocks ⑮ |
| Switch Expressions ⑭ |
| Local-Variable Type Inference ⑩ |
| All The Small Things... ⑨ |
Simple classes ~> simple code
Spilling Beans
Typical Java Bean:
public class Range {
// part I 😀
private final int low;
private final int high;
public Range(int low, int high) {
this.low = low;
this.high = high;
}
}Spilling Beans
public class Range {
// part II 🙄
public int getLow() {
return low;
}
public int getHigh() {
return high;
}
}Spilling Beans
public class Range {
// part III 🤨
@Override
public boolean equals(Object o) {
if (this == o)
return true;
if (o == null || getClass() != o.getClass())
return false;
Range range = (Range) o;
return low == range.low &&
high == range.high;
}
}Spilling Beans
public class Range {
// part IV 🥴
@Override
public int hashCode() {
return Objects.hash(low, high);
}
}Spilling Beans
public class Range {
// part V 😭
@Override
public String toString() {
return "[" + low + "; " + high + "]";
}
}"Java is Verbose"
Range.java is simple:
declares type
Rangedeclares two components,
lowandhigh
Takes 44 lines!
verbose
room for error
unexpressive
Records
// these are "components"
public record Range(int low, int high) {
// compiler generates:
// * canonical constructor
// * accessors low(), high()
// * equals, hashCode, toString
}Records
The API for a record models the state, the whole state, and nothing but the state.
The deal:
give up encapsulation
couple API to internal state
get API for free
Records
The benefits:
no boilerplate for plain "data carriers"
no room for error
makes Java more expressive
On to the details!
Limited Records
Records are limited classes:
no inheritance
can’t use
extendsare
final
component fields are
finalno additional fields
Customizable Records
Records can be customized:
override constructor
add constructors and
static factory methodsoverride accessors
add other methods
override
Objectmethodsimplement interfaces
made serializable
Override Constructors
public Range(int low, int high) {
if (high < low)
throw new IllegalArgumentException();
this.low = low;
this.high = high;
}Override Constructors
Compact canonical constructor:
// executed before fields are assigned
public Range {
if (high < low)
throw new IllegalArgumentException();
}
// arguments can be reassigned
public Range {
if (high < low)
high = low;
}Override Constructors
implicit constructor has same visibility as record
explicit constructors can’t reduce visibility
can’t assign fields in compact form
(happens automatically after its execution)
Add Constructors
Additional constructors work as usual:
public Range(int high) {
this(0, high);
}(Compact canonical constructor can’t delegate.)
Add Static Factories
Additional static factories work as usual:
public static Range open(int low, int high) {
return new Range(low, high + 1);
}Can’t reduce constructor visibility, though.
@Deprecated
// use static factory method instead
public Range { }Override Accessors
Accessors can be overridden:
@Override
public low() {
return Math.max(0, low);
}Not a good example!
The API for a record models the state, the whole state, and nothing but the state.
Implement Interfaces
public record Range(int low, int high)
implements Comparable<Range> {
@Override
public int compareTo(Range other) {
return this.low == other.low
? this.high - other.high
: this.low - other.low;
}
}Serializable Records
public record Range(int low, int high)
implements Serializable { }has default
serialVersionUID0uses
FileOutputStreamand
FileInputStreamas usualdeserializaton calls constructor 🙌
framework support is growing
(e.g. Apache Johnzon for JSON-B)
Summary
use records to replace data carriers
it’s not anti-boilerplate pixie dust
⇝ use only when "the deal" makes sensebeware of limitations
beware of class-building facilites
observe ecosystem for adoption
New Language Features
| Sealed Classes |
| Records ⑯ |
| Pattern Matching ⑯ |
| Text Blocks ⑮ |
| Switch Expressions ⑭ |
| Local-Variable Type Inference ⑩ |
| All The Small Things... ⑨ |
Type check and cast in one operation.
Old-school instanceof
instanceof is cumbersome:
public void feed(Animal animal) {
if (animal instanceof Elephant)
((Elephant) animal).eatPlants();
else if (animal instanceof Tiger)
((Tiger) animal).eatMeat();
}Three things are happening:
type test
type conversaion
variable declaration (implicit)
Pattern Matching
public void feed(Animal animal) {
if (animal instanceof Elephant elephant)
elephant.eatPlants();
else if (animal instanceof Tiger tiger)
tiger.eatMeat();
}animal instanceof Tiger tiger:
does all three things in one operation
tigeris scoped totrue-branch
What is a Pattern?
A pattern is:
a test/predicate
that is applied to a targetpattern variables
that are extracted from the target
if the test passes
// |--------- pattern --------|
// target |----- test ------| variable
animal instanceof Elephant elephantWe will see more patterns in the future.
Pattern Variable Scope
Pattern variable is in scope
where compiler can prove pattern is true:
public void inverted(Object object) {
if (!(object instanceof String string))
throw new IllegalArgumentException();
// after inverted test
System.out.println(string.length());
}Pattern Variable Scope
public void scoped(Object object) {
// later in same expression
if (object instanceof String string
&& string.length() > 50)
System.out.println("Long string");
if (object instanceof String string
// compiler error because || means
// it's not necessarily a string
|| string.length() > 50)
System.out.println("Maybe string");
}Summary
$TARGET instanceof $TYPE $VAR:checks whether
$TARGETis of type$TYPEcreates variable
$TYPE $VAR = $TARGETin scope wherever
instanceof $TYPEistrue
first of many (?) match patterns
keep an eye out for integration with
switch
Preview
switch will be able to use pattern matching:
switch (animal) {
case Elephant elephant
-> elephant.eatPlants();
case Tiger tiger
-> tiger.eatMeat();
}(Strawman syntax!)
New Language Features
| Sealed Classes |
| Records ⑯ |
| Pattern Matching ⑯ |
| Text Blocks ⑮ |
| Switch Expressions ⑭ |
| Local-Variable Type Inference ⑩ |
| All The Small Things... ⑨ |
Multiline strings. Finally.
Multiline Strings
Text blocks are straightforward:
String haikuBlock = """
worker bees can leave
even drones can fly away
the queen is their slave""";
System.out.println(haiku);
// > worker bees can leave
// > even drones can fly away
// > the queen is their slaveline breaks are normalized to
\nintentional indentation remains
accidental indentation is removed
Syntax
can be used in same place
as"string literals"start with
"""and new lineend with
"""on the last line of content
on its own line
Position of closing """ decides
whether string ends with "\n".
Vs String Literals
Compare to:
String haikuLiteral = ""
+ "worker bees can leave\n"
+ " even drones can fly away\n"
+ " the queen is their slave";haikuBlock.equals(haikuLiteral)thanks to string interning even
haikuBlock == haikuLiteral
⇝ No way to discern source at run time!
Line Endings
Line ending depends on configuration.
Source file properties influence semantics?
Text block lines always end with \n!
Escape sequences are translated afterwards:
String windows = """
Windows\r
line\r
endings\r
"""Indentation
Compiler discerns:
accidental indentation
(from code style; gets removed)essential indentation
(within the string; remains)
How?
Accidental Indentation
closing
"""are on their own line
⇝ their indentation is accidentalotherwise, line with smallest indentation
⇝ its indentation is accidental
Indentation
Accidental vs intentional indentation
(separated with |):
String haikuBlock = """
|worker bees can leave
| even drones can fly away
| the queen is their slave""";
String haikuBlock = """
| worker bees can leave
| even drones can fly away
| the queen is their slave
""";Manual Indentation
To manually manage indentation:
String::stripIndentString::indent
Escape Sequences
Text blocks are not raw:
escape sequences work (e.g.
\r)escape sequences are necessary
But: " is not special!
String phrase = """
{
greeting: "hello",
audience: "text blocks",
}
""";⇝ Way fewer escapes in HTML/JSON/SQL/etc.
More on Text Blocks
New Language Features
| Sealed Classes |
| Records ⑯ |
| Pattern Matching ⑯ |
| Text Blocks ⑮ |
| Switch Expressions ⑭ |
| Local-Variable Type Inference ⑩ |
| All The Small Things... ⑨ |
More powerful switch.
Switching
Say you’re facing the dreaded ternary Boolean …
public enum TernaryBoolean {
TRUE,
FALSE,
FILE_NOT_FOUND
}... and want to convert it to a regular Boolean.
Switch Statement
Before Java 14, you might have done this:
boolean result;
switch (ternaryBool) {
case TRUE: result = true; break;
case FALSE: result = false; break;
case FILE_NOT_FOUND:
var ex = new UncheckedIOException(
"This is ridiculous!",
new FileNotFoundException());
throw ex;
default:
var ex2 = new IllegalArgumentException(
"Seriously?! 😠");
throw ex2;
}Switch Statement
Lots of room for improvements:
default fall-through is annoying
resulthandling is roundaboutlacking compiler support is error-prone
Switch Statement
This is better:
public boolean convert(TernaryBoolean ternaryBool) {
switch (ternaryBool) {
case TRUE: return true;
case FALSE: return false;
case FILE_NOT_FOUND:
throw new UncheckedIOException(
"This is ridiculous!",
new FileNotFoundException());
default:
throw new IllegalArgumentException(
"Seriously?! 😠");
}
}Switch Statement
Better:
returnprevents fall-throughresults are created on the spot
But:
defaultis not really necessary……but prevents compile error
on missing branchescreating a method is not always
possible or convenient
Switch Expression
Enter switch expressions:
boolean result = switch(ternaryBool) {
case TRUE -> true;
case FALSE -> false;
case FILE_NOT_FOUND ->
throw new UncheckedIOException(
"This is ridiculous!",
new FileNotFoundException());
};Two things to note:
switch"has a result"
⇝ it’s an expression, not a statementlambda-style arrow syntax
Preview Feature
Note:
In Java 12 & 13, switch expressions are
a preview language feature!
must be enabled with
--enable-preview
(onjavacandjava).in IntelliJ, set the module’s language level to
12 (Preview) - … or 13 (Preview) - …in Eclipse, go to Compiler Settings
and check Enable preview features
Expression vs Statement
Statement:
if (condition)
result = doThis();
else
result = doThat();Expression:
result = condition
? doThis()
: doThat();Expression vs Statement
Statement:
imperative construct
guides computation, but has no result
Expression:
is computed to a result
Expression vs Statement
For switch:
if used with an assignment,
switchbecomes an expressionif used "stand-alone", it’s
treated as a statement
This results in different behavior
(more on that later).
Arrow vs Colon
You can use : and -> with
expressions and statements, e.g.:
boolean result = switch(ternaryBool) {
case TRUE: yield true;
case FALSE: yield false;
case FILE_NOT_FOUND:
throw new UncheckedIOException(
"This is ridiculous!",
new FileNotFoundException());
};switchis used as an expressionyield resultreturnsresult
Arrow vs Colon
Whether you use arrow or colon
results in different behavior
(more on that later).
Switch Evolution
general improvements
multiple case labels
specifics of arrow form
no fall-through
statement blocks
specifics of expressions
poly expression
returning early
exhaustiveness
Multiple Case Labels
Statements and expressions,
in colon and arrow form
can use multiple case labels:
String result = switch (ternaryBool) {
case TRUE, FALSE -> "sane";
// `default, case FILE_NOT_FOUND -> ...`
// does not work (neither does other way
// around), but that makes sense because
// using only `default` suffices
default -> "insane";
};No Fall-Through
Whether used as statement or expression,
the arrow form has no fall-through:
switch (ternaryBool) {
case TRUE, FALSE ->
System.out.println("Bool was sane");
// in colon-form, if `ternaryBool` is `TRUE`
// or `FALSE`, we would see both messages;
// in arrow-form, only one branch is executed
default ->
System.out.println("Bool was insane");
}Statement Blocks
Whether used as statement or expression,
the arrow form can use statement blocks:
boolean result = switch (Bool.random()) {
case TRUE -> {
System.out.println("Bool true");
yield true;
}
case FALSE -> {
System.out.println("Bool false");
yield false;
}
// cases `FILE_NOT_FOUND` and `default`
};Statement Blocks
Natural way to create scope:
boolean result = switch (Bool.random()) {
// cases `TRUE` and `FALSE`
case FILE_NOT_FOUND -> {
var ex = new UncheckedIOException(
"This is ridiculous!",
new FileNotFoundException());
throw ex;
}
default -> {
var ex = new IllegalArgumentException(
"Seriously?! 🤬");
throw ex;
}
};Poly Expression
A poly expression
has no definitive type
can be one of several types
Lambdas are poly expressions:
Function<String, String> fun = s -> s + " ";
UnaryOperator<String> op = s -> s + " ";Poly Expression
Whether in colon or arrow form,
a switch expression is a poly expression.
How it’s type is determined,
depends on the target type:
// target type known: String
String result = switch (ternaryBool) { ... }
// target type unknown
var result = switch (ternaryBool) { ... }Poly Expression
If target type is known, all branches must conform to it:
String result = switch (ternaryBool) {
case TRUE, FALSE -> "sane";
default -> "insane";
};If target type is unknown, the compiler infers a type:
// compiler infers super type of `String` and
// `IllegalArgumentException` ~> `Serializable`
var serializableMessage = switch (bool) {
case TRUE, FALSE -> "sane";
default -> new IllegalArgumentException("insane");
};Returning Early
Whether in colon or arrow form,
you can’t return early from a switch expression:
public String sanity(Bool ternaryBool) {
String result = switch (ternaryBool) {
// compile error:
// "return outside
// of enclosing switch expression"
case TRUE, FALSE -> { return "sane"; }
default -> { return "This is ridiculous!"; }
};
}Exhaustiveness
Whether in colon or arrow form,
a switch expression checks exhaustiveness:
// compile error:
// "the switch expression does not cover
// all possible input values"
boolean result = switch (ternaryBool) {
case TRUE -> true;
// no case for `FALSE`
case FILE_NOT_FOUND ->
throw new UncheckedIOException(
"This is ridiculous!",
new FileNotFoundException());
};Exhaustiveness
No compile error for missing default:
// compiles without `default` branch because
// all cases for `ternaryBool` are covered
boolean result = switch (ternaryBool) {
case TRUE -> true;
case FALSE -> false;
case FILE_NOT_FOUND ->
throw new UncheckedIOException(
"This is ridiculous!",
new FileNotFoundException());
};Compiler adds in default branch.
More on switch
Definitive Guide To Switch Expressions
New Language Features
| Sealed Classes |
| Records ⑯ |
| Pattern Matching ⑯ |
| Text Blocks ⑮ |
| Switch Expressions ⑭ |
| Local-Variable Type Inference ⑩ |
| All The Small Things... ⑨ |
Type inference with var.
Less typing, but still strongly typed.
Type Duplication
We’re used to duplicating
type information:
URL nipafx = new URL("https://nipafx.dev");
URLConnection connection = nipafx.openConnection();
Reader reader = new BufferedReader(
new InputStreamReader(
connection.getInputStream()));Not so bad?
Type Duplication
What about this?
No no = new No();
AmountIncrease<BigDecimal> more =
new BigDecimalAmountIncrease();
HorizontalConnection<LinePosition, LinePosition>
jumping =
new HorizontalLinePositionConnection();
Variable variable = new Constant(5);
List<String> names = List.of("Max", "Maria");Type Deduplication
Can’t somebody else do that?
Compiler knows the types!
Enter var:
var nipafx = new URL("https://nipafx.dev");
var connection = nipafx.openConnection();
var reader = new BufferedReader(
new InputStreamReader(
connection.getInputStream()));Locality
How much information is used for inference?
type inference can be
arbitrarily complex/powerfulcritical resource is not
compiler but developercode should be readable
(without compiler/IDE)
⇝ Better to keep it simple!
"Action at a distance"
// inferred as `int`
var id = 123;
if (id < 100) {
// very long branch
} else {
// oh boy, much more code...
}
// now we add this line:
id = "124";What type should id be?
Where does the error show up?
Rules of var
Hence, var only works in limited scopes:
compiler infers type from right-hand side
⇝ rhs has to exist and define a typeonly works for local variables,
for,try
⇝ novaron fields or in method signaturesalso on lambda parameters ⑪
⇝ annotate inferred type on lambda parameters
Rules of var
Two more:
not a keyword, but a reserved type name
⇝ variables/fields can be namedvarcompiler writes type into bytecode
⇝ no run-time component
What About Readability?
This is about readability!
less redundancy
more intermediate variables
more focus on variable names
aligned variable names
Aligned Variable Names
var no = new No();
var more = new BigDecimalAmountIncrease();
var jumping = new HorizontalLinePositionConnection();
var variable = new Constant(5);
var names = List.of("Max", "Maria");What About Readability?
Still think omitting types is always bad?
Ever wrote a lambda without declaring types?
rhetoricalQuestion.answer(yes -> "see my point?");Style Guidelines
Principles from the official style guidelines:
Reading code is more important than writing it.
Code should be clear from local reasoning.
Code readability shouldn’t depend on IDEs.
Explicit types are a tradeoff.
Style Guidelines
Guidelines:
Choose variable names that provide useful info.
Minimize the scope of local variables.
Consider
varwhen the initializer provides sufficient information to the reader.Use
varto break up chained or nested expressions.Don’t worry too much about "programming to the interface".
Take care when using
varwith diamonds or generics.Take care when using
varwith literals.
Style Guidelines
Choose variable names that provide useful info.
/* ✘ */ var u = UserRepository.findUser(id);
/* ✔ */ var user = UserRepository.findUser(id);
/* 👍*/ var userToLogIn = UserRepository.findUser(id);Style Guidelines
Minimize the scope of local variables.
// ✘
var id = 123;
if (id < 100) {
// very long branch
} else {
// oh boy, much more code...
}
LOGGER.info("... " + id);
// ✔ replace branches with method callsStyle Guidelines
Consider
varwhen the initializer provides
sufficient information to the reader.
/* ✘ */ var user = Repository.find(id);
/* ✔ */ var user = UserRepository.findUser(id);
/* 👍*/ var user = new User(id);Style Guidelines
Use
varto break up chained or nested expressions.
// ✘
return Canvas
.activeCanvas()
.drawings()
.filter(Drawing::isLine)
.map(drawing -> (HorizontalConnection) drawing)
// now we have lines
.filter(line -> length(line) == 7)
.map(this::generateSquare)
// now we have squares
.map(this::createRandomColoredSquare)
.map(this::createRandomBorderedSquare)
.collect(toList());Style Guidelines
Use
varto break up chained or nested expressions.
// ✔
var lines = Canvas
.activeCanvas()
.drawings()
.filter(Drawing::isLine)
.map(drawing -> (HorizontalConnection) drawing)
var squares = lines
.filter(line -> length(line) == 7)
.map(this::generateSquare);
return squares
.map(this::createRandomColoredSquare)
.map(this::createRandomBorderedSquare)
.collect(toList());Style Guidelines
Don’t worry too much about
"programming to the interface".
// inferred as `ArrayList` (not `List`),
// but that's ok
var users = new ArrayList<User>();Careful when refactoring:
extracting methods that use
var-ed variables
puts concrete types into method signatureslook out and replace with most general type
Style Guidelines
Take care when using
varwith diamonds or generics.
// ✘ infers `ArrayList<Object>`
var users = new ArrayList<>();
// ✔ infers `ArrayList<User>`
var users = new ArrayList<User>();Style Guidelines
Take care when using
varwith literals.
// ✘ when used with `var`, these
// variables become `int`
byte b = 42;
short s = 42;
long l = 42;More on var
First Contact With
varIn Java 10
💻 tiny.cc/java-var / ▶ tiny.cc/java-var-ytcheat sheet (⇜ print when getting started!)
varand …
New Language Features
| All The Cool Things... ⑩⑭⑮ |
| Private Interface Methods ⑨ |
| Try-With-Resources ⑨ |
| Diamond Operator ⑨ |
| SafeVarargs ⑨ |
| Deprecation Warnings ⑨⑯ |
Enabling reuse between default methods.
No Reuse
public interface InJava8 {
default boolean evenSum(int... numbers) {
return sum(numbers) % 2 == 0;
}
default boolean oddSum(int... numbers) {
return sum(numbers) % 2 == 1;
}
default int sum(int[] numbers) {
return IntStream.of(numbers).sum();
}
}Private Methods
public interface InJava9 {
private int sum(int[] numbers) {
return IntStream.of(numbers).sum();
}
}Just like private methods in abstract classes:
must be implemented
can not be overriden
can only be called in same source file
New Language Features
| All The Cool Things... ⑩⑭⑮ |
| Private Interface Methods ⑨ |
| Try-With-Resources ⑨ |
| Diamond Operator ⑨ |
| SafeVarargs ⑨ |
| Deprecation Warnings ⑨⑯ |
Making try-with-resources blocks cleaner.
Useless Variable
void doSomethingWith(Connection connection)
throws Exception {
try(Connection c = connection) {
c.doSomething();
}
}Why is c necessary?
Why is c necessary?
target of
close()must be obvious
⇝ resource should not be reassignedeasiest if resource is final
easiest if resource must be assigned
and can be made implicitly final
try(Connection c = connection)Effectively Final Resource
But since Java 8 we have effectively final!
This works in Java 9:
void doSomethingWith(Connection connection)
throws Exception {
try(connection) {
connection.doSomething();
}
}compiler knows that
connectionis not reassigneddevelopers know what effectively final means
New Language Features
| All The Cool Things... ⑩⑭⑮ |
| Private Interface Methods ⑨ |
| Try-With-Resources ⑨ |
| Diamond Operator ⑨ |
| SafeVarargs ⑨ |
| Deprecation Warnings ⑨⑯ |
A little more type inference.
Diamond Operator
Maybe the best example:
List<String> strings = new ArrayList<>();used at a constructor call
tells Java to infer the parametric type
Anonymous Classes
Diamond did not work with anonymous classes:
<T> Box<T> createBox(T content) {
// we have to put the `T` here :(
return new Box<T>(content) { };
}Reason are non-denotable types:
might be inferred by compiler
for anonymous classescan not be expressed by JVM
Infer Denotable Types
Java 9 infers denotable types:
<T> Box<T> createBox(T content) {
return new Box<>(content) { };
}Gives compile error if type is non-denotable:
Box<?> createCrazyBox(Object content) {
List<?> innerList = Arrays.asList(content);
// compile error
return new Box<>(innerList) { };
}New Language Features
| All The Cool Things... ⑩⑭⑮ |
| Private Interface Methods ⑨ |
| Try-With-Resources ⑨ |
| Diamond Operator ⑨ |
| SafeVarargs ⑨ |
| Deprecation Warnings ⑨⑯ |
One less warning you couldn’t do anything about.
Heap Pollution
Innocent looking code…
private <T> Optional<T> firstNonNull(T... args) {
return stream(args)
.filter(Objects::nonNull)
.findFirst();
}Compiler warns (on call site, too):
Possible heap pollution from
parameterized vararg typeHeap Pollution?
For generic varargs argument T… args,
you must not depend on it being a T[]!
private <T> T[] replaceTwoNulls(
T value, T first, T second) {
return replaceAllNulls(value, first, second);
}
private <T> T[] replaceAllNulls(T value, T... args) {
// loop over `args`, replacing `null` with `value`
return args;
}Compiler Warning
Compiler is aware of the problem and warns you.
If you think, everything’s under control:
@SafeVarargs
private <T> Optional<T> firstNonNull(T... args) {
return // [...]
}Or not… In Java 8 this is a compile error!
Invalid SafeVarargs annotation. Instance
method <T>firstNonNull(T...) is not final.But Why?
The @SafeVarargs annotation:
tells the caller that all is fine
only makes sense on methods
that can not be overriden
Which methods can’t be overriden?
⇝ final methods
What about private methods?
⇝ Damn! 😭
@SafeVarargs on Private Methods
Looong story, here’s the point:
In Java 9 @SafeVarargs
can be applied to private methods.
New Language Features
| All The Cool Things... ⑩⑭⑮ |
| Private Interface Methods ⑨ |
| Try-With-Resources ⑨ |
| Diamond Operator ⑨ |
| SafeVarargs ⑨ |
| Deprecation Warnings ⑨⑯ |
Some come, some go.
New Deprecation Warnings
Project Valhalla will bing inline classes:
code like a class, work like an
inthave no identity
allow no identity-based operations
Value-based classes are their precursors.
Identity-based
What is identity-based?
constructor calls
mutability
synchronization
serialization
These need to be prevented
for inline and value-based classes.
Deprecations
Java 16 designates primitive wrapper classes
(Integer, Long, Float, Double, etc)
as value-based classes.
Warning on both lines:
// use Integer::valueOf instead
Integer answer = new Integer(42);
// don't synchronize on values
synchronize(answer) { /*... */ }constructors are deprecated for removal
synchronization yields warning
Deprecation Warnings
Should this code emit a warning?
// LineNumberInputStream is deprecated
import java.io.LineNumberInputStream;
public class DeprecatedImports {
LineNumberInputStream stream;
}// LineNumberInputStream is deprecated
import java.io.LineNumberInputStream;
@Deprecated
public class DeprecatedImports {
LineNumberInputStream stream;
}Not On Imports
Java 9 no longer emits warnings
for importing deprecated members.
Warning free:
import java.io.LineNumberInputStream;
@Deprecated
public class DeprecatedImports {
LineNumberInputStream stream;
}Updated APIs
| String ⑪⑫ |
| Stream ⑨⑩⑫⑯ |
| Optional ⑨⑩⑪ |
| OS Processes ⑨ |
| Completable Future ⑫ |
Existing APIs are continuously improved.
Updated APIs
| String ⑪⑫ |
| Stream ⑨⑩⑫⑯ |
| Optional ⑨⑩⑪ |
| OS Processes ⑨ |
| Completable Future ⑫ |
Small improvements to String.
Strip White Space ⑪
Getting rid of white space:
String strip();
String stripLeading();
String stripTrailing();Only at beginning and end of string:
" foo bar ".strip().equals("foo bar");What About Trim?
Wait, what about trim()?
trim()defines white space as:any character whose codepoint
is less than or equal to'U+0020'
(the space character)strip()relies onCharacter::isWhitespace,
which covers many more cases
Is Blank? ⑪
Is a string only white space?
boolean isBlank();Functionally equivalent to:
string.isBlank() == string.strip().isEmpty();Life Hack
As soon as Java APIs get new method,
scour StackOverflow for easy karma!

Life Hack
Formerly accepted answer:
😍
Life Hack ⑪
Ta-da!
Streaming Lines ⑪
Processing a string’s lines:
Stream<String> lines();splits a string on
"\n","\r","\r\n"lines do not include terminator
more performant than
split("\R")lazy!
Changing Indentation ⑫
Use String::indent to add or remove
leading white space:
String oneTwo = " one\n two\n";
oneTwo.indent(0).equals(" one\n two\n");
oneTwo.indent(1).equals(" one\n two\n");
oneTwo.indent(-1).equals("one\n two\n");
oneTwo.indent(-2).equals("one\ntwo\n");Would have been nice to pass resulting indentation,
not change in indentation.
Changing Indentation ⑫
String::indent normalizes line endings
so each line ends in \n:
"1\n2".indent(0).equals("1\n2\n");
"1\r\n2".indent(0).equals("1\n2\n");
"1\r2\n".indent(0).equals("1\n2\n");
"1\n2\n".indent(0).equals("1\n2\n");Transforming Strings ⑫
New method on String:
public <R> R transform(Function<String, R> f) {
return f.apply(this);
}Use to chain calls instead of nesting them:
User newUser = parse(clean(input));
User newUser = input
.transform(this::clean)
.transform(this::parse);Makes more sense at end of long call chain
(stream pipeline?) to chain more calls.
Transforming things
Maybe other classes get transform, too!
Great for "chain-friendly" APIs like Stream, Optional:
// in a museum...
tourists.stream()
.map(this::letEnter)
.transform(this::groupsOfFive)
.forEach(this::giveTour)
Stream<TouristGroup> groupsOfFive(
Stream<Tourist> tourists) {
// this is not trivial,
// but at least possible
}⇝ Practice with String::transform!
Updated APIs
| String ⑪⑫ |
| Stream ⑨⑩⑫⑯ |
| Optional ⑨⑩⑪ |
| OS Processes ⑨ |
| Completable Future ⑫ |
Small improvements to Java 8 streams.
Of Nullable ⑨
Create a stream of zero or one elements:
long zero = Stream.ofNullable(null).count();
long one = Stream.ofNullable("42").count();Iterate ⑨
To use for even less…
iterate(
T seed,
Predicate<T> hasNext,
UnaryOperator<T> next);Example:
Stream
.iterate(1, i -> i<=10, i -> 2*i)
.forEach(System.out::println);
// output: 1 2 4 8Iterate ⑨
Counter Example:
Enumeration<Integer> en = // ...
Stream.iterate(
en.nextElement(),
el -> en.hasMoreElements(),
el -> en.nextElement())
.forEach(System.out::println);first
nextElement()then
hasMoreElements()⇝ fail
Take While ⑨
Stream as long as a condition is true:
Stream<T> takeWhile(Predicate<T> predicate);Example:
Stream.of("a-", "b-", "c-", "", "e-")
.takeWhile(s -> !s.isEmpty())
.forEach(System.out::print);
// output: a-b-c-Drop While ⑨
Ignore as long as a condition is true:
Stream<T> dropWhile(Predicate<T> predicate);Example:
Stream.of("a-", "b-", "c-", "de-", "f-")
.dropWhile(s -> s.length() <= 2)
.forEach(System.out::print);
// output: de-f-Collect Unmodifiable ⑩
Create unmodifiable collections
(in the sense of List::of et al)
with Collectors:
Collector<T, ?, List<T>> toUnmodifiableList();
Collector<T, ?, Set<T>> toUnmodifiableSet();
Collector<T, ?, Map<K,U>> toUnmodifiableMap(
Function<T, K> keyMapper,
Function<T, U> valueMapper);
// plus overload with merge functionTeeing Collector ⑫
Collect stream elements in two collectors
and combine their results:
// on Collectors
Collector<T, ?, R> teeing(
Collector<T, ?, R1> downstream1,
Collector<T, ?, R2> downstream2,
BiFunction<R1, R2, R> merger);Teeing Collector ⑫
Example:
Statistics stats = Stream
.of(1, 2, 4, 5)
.collect(teeing(
// Collector<Integer, ?, Integer>
summingInt(i -> i),
// Collector<Integer, ?, Double>
averagingInt(i -> i),
// BiFunction<Integer, Double, Statistics>
Statistics::of));
// stats = Statistics {sum=12, average=3.0}Declarative Flat Map
Stream::flatMap is great, but:
sometimes you can’t easily
map to aStreamcreating small/empty streams
can harm performance
For these niche (!) cases,
there’s Stream::mapMulti.
Imperative Flat Map ⑯
<R> Stream<R> mapMulti(
BiConsumer<T, Consumer<R>> mapper)BiConsumer is called for each element:
gets the element
Tgets a
Consumer<R>can pass arbitrarily many
R-s
to the consumerthey show up downstream
So like flatMap, but imperative.
Map Multi Examples
Stream.of(1, 2, 3, 4)
// changes nothing, just passes on elements
.mapMulti((el, ds) -> ds.accept(el));
Stream
.of(Optional.of("0"), Optional.empty())
// unpacks Optionals
.mapMulti((el, ds) -> el.ifPresent(ds));
Stream
.of(Optional.of("0"), Optional.empty())
.mapMulti(Optional::ifPresent);Type Witness
Unfortunately, mapMulti confuses
parametric type inference:
List<String> strings = Stream
.of(Optional.of("0"), Optional.empty())
// without <String>, collect returns List<Object>
.<String> mapMulti(Optional::ifPresent)
.collect(toList());Immediate To List ⑯
How often have you written
.collect(Collectors.toList())?
Answer: too damn often!
But no more:
List<String> strings = Stream
.of("A", "B", "C")
// some stream stuff
.toList()List Properties
Like collection factories,
the returned lists are:
immutable/unmodifiable
Unlike them:
they can contain
null
Updated APIs
| String ⑪⑫ |
| Stream ⑨⑩⑫⑯ |
| Optional ⑨⑩⑪ |
| OS Processes ⑨ |
| Completable Future ⑫ |
Small improvements to Java 8 Optional.
Or ⑨
Choose a non-empty Optional:
Optional<T> or(Supplier<Optional<T>> supplier);Find in Many Places
public interface Search {
Optional<Customer> inMemory(String id);
Optional<Customer> onDisk(String id);
Optional<Customer> remotely(String id);
default Optional<Customer> anywhere(String id) {
return inMemory(id)
.or(() -> onDisk(id))
.or(() -> remotely(id));
}
}If Present Or Else ⑨
Like ifPresent but do something if empty:
void ifPresentOrElse(
Consumer<T> action,
Runnable emptyAction);Example:
void logLogin(String id) {
findCustomer(id)
.ifPresentOrElse(
this::logCustomerLogin,
() -> logUnknownLogin(id));
}Stream ⑨
Turns an Optional into a Stream
of zero or one elements:
Stream<T> stream();Filter-Map …
private Optional<Customer> findCustomer(String id) {
// ...
}
Stream<Customer> findCustomers(List<String> ids) {
return ids.stream()
.map(this::findCustomer)
// now we have a Stream<Optional<Customer>>
.filter(Optional::isPresent)
.map(Optional::get)
}… in one Step
private Optional<Customer> findCustomer(String id) {
// ...
}
Stream<Customer> findCustomers(List<String> ids) {
return ids.stream()
.map(this::findCustomer)
// now we have a Stream<Optional<Customer>>
// we can now filter-map in one step
.flatMap(Optional::stream)
}From Eager to Lazy
List<Order> getOrders(Customer c) is expensive:
List<Order> findOrdersForCustomer(String id) {
return findCustomer(id)
.map(this::getOrders) // eager
.orElse(new ArrayList<>());
}
Stream<Order> findOrdersForCustomer(String id) {
return findCustomer(id)
.stream()
.map(this::getOrders) // lazy
.flatMap(List::stream);
}Or Else Throw ⑩
Optional::get invites misuse
by calling it reflexively.
Maybe get wasn’t the best name?
New:
T orElseThrow()Works exactly as get,
but more self-documenting.
Aligned Names
Name in line with other accessors:
T orElse(T other)
T orElseGet(Supplier<T> supplier)
T orElseThrow()
throws NoSuchElementException
T orElseThrow(
Supplier<EX> exceptionSupplier)
throws EXGet Considered Harmful
JDK-8160606
will deprecate
Optional::get.
when?
for removal?
We’ll see…
Is Empty ⑪
No more !foo.isPresent():
boolean isEmpty()Does exactly what
you think it does.
Updated APIs
| String ⑪⑫ |
| Stream ⑨⑩⑫⑯ |
| Optional ⑨⑩⑪ |
| OS Processes ⑨ |
| Completable Future ⑫ |
Improving interaction with OS processes.
Simple Example
ls /home/nipa/tmp | grep pdfPath dir = Paths.get("/home/nipa/tmp");
ProcessBuilder ls = new ProcessBuilder()
.command("ls")
.directory(dir.toFile());
ProcessBuilder grepPdf = new ProcessBuilder()
.command("grep", "pdf")
.redirectOutput(Redirect.INHERIT);
List<Process> lsThenGrep = ProcessBuilder
.startPipeline(List.of(ls, grepPdf));Extended Process
Cool new methods on Process:
boolean supportsNormalTermination();long pid();CompletableFuture<Process> onExit();Stream<ProcessHandle> children();Stream<ProcessHandle> descendants();ProcessHandle toHandle();
New ProcessHandle
New functionality actually comes from ProcessHandle.
Interesting static methods:
Stream<ProcessHandle> allProcesses();Optional<ProcessHandle> of(long pid);ProcessHandle current();
More Information
ProcessHandle can return Info:
command, arguments
start time
CPU time
Updated APIs
| String ⑪⑫ |
| Stream ⑨⑩⑫⑯ |
| Optional ⑨⑩⑪ |
| OS Processes ⑨ |
| Completable Future ⑫ |
Asynchronous error recovery.
Recap on API Basics
// start an asynchronous computation
public static CompletableFuture<T> supplyAsync(
Supplier<T>);
// attach further steps
public CompletableFuture<U> thenApply(Function<T, U>);
public CompletableFuture<U> thenCompose(
Function<T, CompletableFuture<U>);
public CompletableFuture<Void> thenAccept(Consumer<T>);
// wait for the computation to finish and get result
public T join();Recap on API Basics
Example:
public void loadWebPage() {
String url = "https://nipafx.dev";
CompletableFuture<WebPage> future = CompletableFuture
.supplyAsync(() -> webRequest(url))
.thenApply(html -> new WebPage(url, html));
// ... do other stuff
WebPage page = future.join();
}
private String webRequest(String url) {
// make request to URL and return HTML
// (this can take a while)
}Recap on Completion
A pipeline or stage completes when
the underlying computation terminates.
it completes normally if
the computation yields a resultit completes exceptionally if
the computation results in an exception
Recap on Error Recovery
Two methods to recover errors:
// turn the error into a result
CompletableFuture<T> exceptionally(Function<Throwable, T>);
// turn the result or error into a new result
CompletableFuture<U> handle(BiFunction<T, Throwable, U>);They turn exceptional completion of the previous stage
into normal completion of the new stage.
Recap on Error Recovery
Example:
loadUser(id)
.thenCompose(this::loadUserHistory)
.thenCompose(this::createRecommendations)
.exceptionally(ex -> {
log.warn("Recommendation error", ex)
return createDefaultRecommendations();
})
.thenAccept(this::respondWithRecommendations);Composeable Error Recovery ⑫
Error recovery accepts functions
that produce CompletableFuture:
exceptionallyCompose(
Function<Throwable, CompletionStage<T>>)Recap on (A)Synchronicity
Which threads actually compute the stages?
supplyAsync(Supplier<T>)is executed
in the common fork/join poolfor other stages it’s undefined:
could be the same thread as the previous stage
could be another thread in the pool
could be the thread calling
thenAcceptet al.
How to force async computation?
Recap on (A)Synchronicity
All "composing" methods
have an …Async companion, e.g.:
thenApplyAsync(Function<T, U>);
thenAcceptAsync(Consumer<T>);They submit each stage as a separate task
to the common fork/join pool.
Async Error Recovery ⑫
Error recovery can be asynchronous:
CompletableFuture<T> exceptionallyAsync(
Function<Throwable, T>)
CompletableFuture<T> exceptionallyComposeAsync(
Function<Throwable, CompletableFuture<T>>)There are overloads that accept Executor.
A Mixed Bag Of Updated APIs
Two great sources on
Java API changes
between versions:
A Mixed Bag Of Updated APIs
In Java 9:
Many lower-level APIs.
A Mixed Bag Of New I/O Methods
In Java 9 to 11:
Path.of(String); // ~ Paths.get(String) ⑪
Files.readString(Path); // ⑪
Files.writeString(Path, CharSequence, ...); // ⑪
Reader.transferTo(Writer); // ⑩
InputStream.transferTo(OutputStream); // ⑨
Reader.nullReader(); // ⑪
Writer.nullWriter(); // ⑪
InputStream.nullInputStream(); // ⑪
OutputStream.nullOutputStream(); // ⑪A Mixed Bag Of New I/O Methods
In Java 12 and 13:
Files.mismatch(Path, Path); // ⑫
FileSystems.newFileSystem(Path, ...); // ⑬
ByteBuffer.get(int, ...) // ⑬
ByteBuffer.put(int, ...) // ⑬A Mixed Bag Of New Math Methods
// in Java 14
StrictMath.decrementExact(int);
StrictMath.decrementExact(long);
StrictMath.incrementExact(int);
StrictMath.incrementExact(long);
StrictMath.negateExact(int);
StrictMath.negateExact(long);
// in Java 15
Math.absExact(int)
Math.absExact(long)
StrictMath.absExact(int)
StrictMath.absExact(long)A Mixed Bag Of New Methods
In Java 10:
DateTimeFormatter.localizedBy(Locale);In Java 11:
Collection.toArray(IntFunction<T[]>);
Predicate.not(Predicate<T>); // static
Pattern.asMatchPredicate(); // ⇝ Predicate<String>A Mixed Bag Of New Methods
In Java 12:
NumberFormat::getCompactNumberInstance
In Java 15:
// instance version of String::format
String.formatted(Object... args);A Mixed Bag Of New Methods
In Java 16:
Objects.checkIndex(long, long)
Objects.checkFromToIndex(long, long, long)
Objects.checkFromIndexSize(long, long, long)New APIs
| Collection Factories ⑨⑩ |
| Reactive Streams ⑨ |
| Reactive HTTP/2 Client ⑪⑯ |
| Stack-Walking ⑨ |
New APIs are added over time.
New APIs
| Collection Factories ⑨⑩ |
| Reactive Streams ⑨ |
| Reactive HTTP/2 Client ⑪⑯ |
| Stack-Walking ⑨ |
Easy creation of ad-hoc collections.
Hope is Pain
Wouldn’t this be awesome?
List<String> list = [ "a", "b", "c" ];
Map<String, Integer> map = [ "one" = 1, "two" = 2 ];Not gonna happen!
language change is costly
binds language to collection framework
strongly favors specific collections
Next Best Thing ⑨
List<String> list = List.of("a", "b", "c");
Map<String, Integer> mapImmediate = Map.of(
"one", 1,
"two", 2,
"three", 3);
Map<String, Integer> mapEntries = Map.ofEntries(
Map.entry("one", 1),
Map.entry("two", 2),
Map.entry("three", 3));Interesting Details
collections are immutable
(no immutability in types, though)collections are value-based
nullelements/keys/values are forbiddeniteration order is random between JVM starts
(except for lists, of course!)
Immutable Copies ⑩
Creating immutable copies:
/* on List */ List<E> copyOf(Collection<E> coll);
/* on Set */ Set<E> copyOf(Collection<E> coll);
/* on Map */ Map<K, V> copyOf(Map<K,V> map);Great for defensive copies:
public Customer(List<Order> orders) {
this.orders = List.copyOf(orders);
}New APIs
| Collection Factories ⑨⑩ |
| Reactive Streams ⑨ |
| Reactive HTTP/2 Client ⑪⑯ |
| Stack-Walking ⑨ |
The JDK as common ground
for reactive stream libraries.
Reactive Types
Publisherproduces items to consume
can be subscribed to
Subscribersubscribes to publisher
onNext,onError,onComplete
Subscriptionconnection from subscriber to publisher
request,cancel
Reactive Flow
Subscribing
create
Publisher pubandSubscriber subcall
pub.subscribe(sub)pub creates
Subscription script
and callssub.onSubscription(script)subcan storescript
Reactive Flow
Streaming
subcallsscript.request(10)pubcallssub.onNext(element)(max 10x)
Canceling
pubmay callsub.OnError(err)
orsub.onComplete()submay callscript.cancel()
Reactive APIs?
JDK only provides three interfaces
and one simple implementation.
(Also called Flow API.)
So far, only reactive HTTP/2 API ⑪ uses Flow.
New APIs
| Collection Factories ⑨⑩ |
| Reactive Streams ⑨ |
| Reactive HTTP/2 Client ⑪⑯ |
| Stack-Walking ⑨ |
HTTP/2! And reactive! Woot!
Basic Flow
To send a request and get a response:
use builder to create immutable
HttpClientuse builder to create immutable
HttpRequestpass request to client to receive
HttpResponse
Building a Client
HttpClient client = HttpClient.newBuilder()
.version(HTTP_2)
.connectTimeout(ofSeconds(5))
.followRedirects(ALWAYS)
.build();More options:
proxy
SSL context/parameters
authenticator
cookie handler
Building a Request
HttpRequest request = HttpRequest.newBuilder()
.GET()
.uri(URI.create("https://nipafx.dev"))
.setHeader("header-name", "header-value")
.build();more HTTP methods (duh!)
individual timeout
individual HTTP version
request
"100 CONTINUE"before sending bodycreate prefilled builder from existing request ⑯
Receiving a Response
// the generic `String`...
HttpResponse<String> response = client.send(
request,
// ... comes from this body handler ...
BodyHandlers.ofString());
// ... and defines `body()`s return type
String body = response.body();status code, headers, SSL session
request
intermediate responses
(redirection, authentication)
Reactive?
Great, but where’s the reactive sauce?
Three places:
send request asynchronously
provide request body with
Publisher<ByteBuffer>receive response body with
Subscriber<String>or
Subscriber<List<ByteBuffer>>
Asynchronous Request
Submit request to thread pool until completes:
CompletableFuture<String> responseBody = client
.sendAsync(request, BodyHandlers.ofString())
.thenApply(this::logHeaders)
.thenApply(HttpResponse::body);uses "a default executor" to field requests
pool can be defined when client is built with
HttpClient.Builder.executor(Executor)
Reactive Request Body
If a request has a long body,
no need to prepare it in its entirety:
Publisher<ByteBuffer> body = // ...
HttpRequest post = HttpRequest.newBuilder()
.POST(BodyPublishers.fromPublisher(body))
.build();
client.send(post, BodyHandlers.ofString())clientsubscribes tobodyas
bodypublishes byte buffers,
clientsends them over the wire
Reactive Response Body
If a response has a long body,
no need to wait before processing:
Subscriber<String> body = // ...
HttpResponse<Void> response = client.send(
request,
BodyHandlers.fromLineSubscriber(subscriber));clientsubscribesbodyto itselfas
clientreceives response bytes,
it parses to lines and passes tobody
Reactive Benefits
Benefits of reactive
request/response bodies:
receiver applies backpressure:
on requests,
clienton responses,
body
bodycontrols memory usageearly errors lead to partial processing
need "reactive tools" to create
body
from higher-level Java objects (e.g.File)
Web Sockets
Short version:
there’s a class
WebSocketsend[Text|Binary|…]methods
returnCompletableFuturesocket calls
Listenermethods
on[Text|Binary|…]
(WebSocket and Listener behave like
Subscription and Subscriber.)
No long version. 😛
New APIs
| Collection Factories ⑨⑩ |
| Reactive Streams ⑨ |
| Reactive HTTP/2 Client ⑪⑯ |
| Stack-Walking ⑨ |
Examining the stack faster and easier.
StackWalker::forEach
void forEach (Consumer<StackFrame>);public static void main(String[] args) { one(); }
static void one() { two(); }
static void two() {
StackWalker.getInstance()
.forEach(System.out::println);
}
// output
StackWalkingExample.two(StackWalking.java:14)
StackWalkingExample.one(StackWalking.java:11)
StackWalkingExample.main(StackWalking.java:10)StackWalker::walk
T walk (Function<Stream<StackFrame>, T>);static void three() {
String line = StackWalker.getInstance().walk(
frames -> frames
.filter(f -> f.getMethodName().contains("one"))
.findFirst()
.map(f -> "Line " + f.getLineNumber())
.orElse("Unknown line");
);
System.out.println(line);
}
// output
Line 11Options
getInstance takes options as arguments:
SHOW_REFLECT_FRAMESfor reflection framesSHOW_HIDDEN_FRAMESe.g. for lambda framesRETAIN_CLASS_REFERENCEforClass<?>
Frames and Traces
forEach and walk operate on StackFrame:
class and method name
class as
Class<?>bytecode index and isNative
Can upgrade to StackTraceElement (expensive):
file name and line number
Performance I
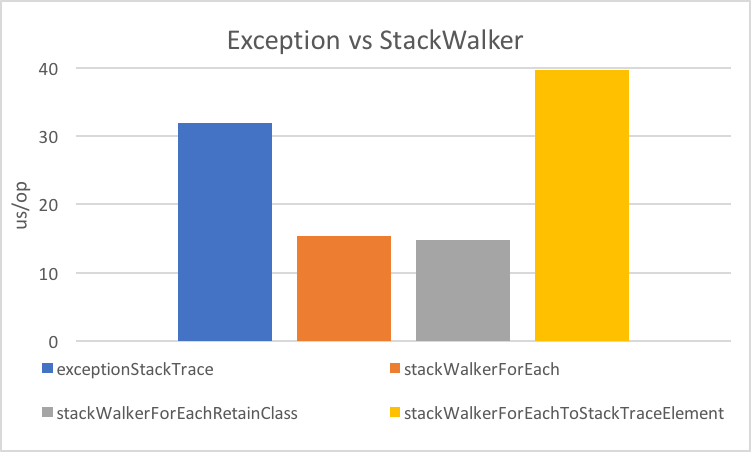
Performance II
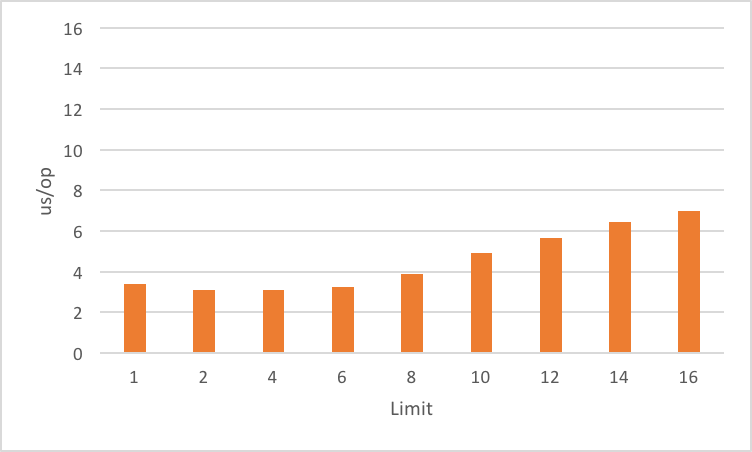
Performance III
creating
StackTraceElementis expensive
(for file name and line number)lazy evaluation pays off for partial traversal
(Benchmarks performed by Arnaud Roger)
A Mixed Bag Of New APIs
In Java 9:
A Mixed Bag Of New APIs
In Java 12:
CompactNumberFormat(JDK-8188147)
In Java 14:
And often lots of low-level APIs.
JVM Features
| Helpful NPEs ⑭ |
| Launch Source File ⑪ |
| Unified Logging ⑨ |
| Multi-Release JARs ⑨ |
| Redirected Platform Logging ⑨ |
JVM Features
| Helpful NPEs ⑭ |
| Launch Source File ⑪ |
| Unified Logging ⑨ |
| Multi-Release JARs ⑨ |
| Redirected Platform Logging ⑨ |
Finally can NPEs be helpful!
Typical NPEs
java.lang.NullPointerException
at dev.nipafx.Regular.doing(Regular.java:28)
at dev.nipafx.Business.its(Business.java:20)
at dev.nipafx.Code.thing(Code.java:11)Ok-ish for coders, but suck for everybody else.
Helpful NPEs
With -XX:+ShowCodeDetailsInExceptionMessages:
java.lang.NullPointerException:
Cannot invoke "String.length()" because the return
value of "dev.nipafx.Irregular.doing()"
is null
at dev.nipafx.Regular.doing(Regular.java:28)
at dev.nipafx.Business.its(Business.java:20)
at dev.nipafx.Code.thing(Code.java:11)Why the flag?
The command line option
is needed (for now), because:
performance
security
compatibility
But:
It is intended to enable code details
in exception messages by default
in a later release.
JVM Features
| Helpful NPEs ⑭ |
| Launch Source File ⑪ |
| Unified Logging ⑨ |
| Multi-Release JARs ⑨ |
| Redirected Platform Logging ⑨ |
Faster feedback with fewer tools.
Launching A Single Source File
Compiling and running
simple Java programs is verbose.
Not any more!
java HelloJava11.javaBackground
How it works:
compiles source into memory
runs from there
Details:
requires module jdk.compiler
processes options like class/module path et al.
interprets
@filesfor easier option management
Use Cases
Mostly similar to jshell:
easier demonstrations
more portable examples
experimentation with new language features
(combine with--enable-preview)
But also: script files!
Scripts
Steps towards easier scripting:
arbitrary file names
shebang support
Arbitrary File Names
Use --source if file doesn’t end in .java:
java --source 11 hello-java-11Shebang Support
To create "proper scripts":
include shebang in source:
#!/opt/jdk-11/bin/java --source 11name script and make it executable
execute it as any other script:
# from current directory: ./hello-java-11 # from PATH: hello-java-11
JVM Features
| Helpful NPEs ⑭ |
| Launch Source File ⑪ |
| Unified Logging ⑨ |
| Multi-Release JARs ⑨ |
| Redirected Platform Logging ⑨ |
Observing the JVM at work.
Unified Logging
New logging infrastructure for the JVM
(e.g. OS interaction, threading, GC, etc.):
JVM log messages pass through new mechanism
works similar to known logging frameworks:
textual messages
log level
time stamps
meta information (like subsystem)
output can be configured with
-Xlog
Unified Logging
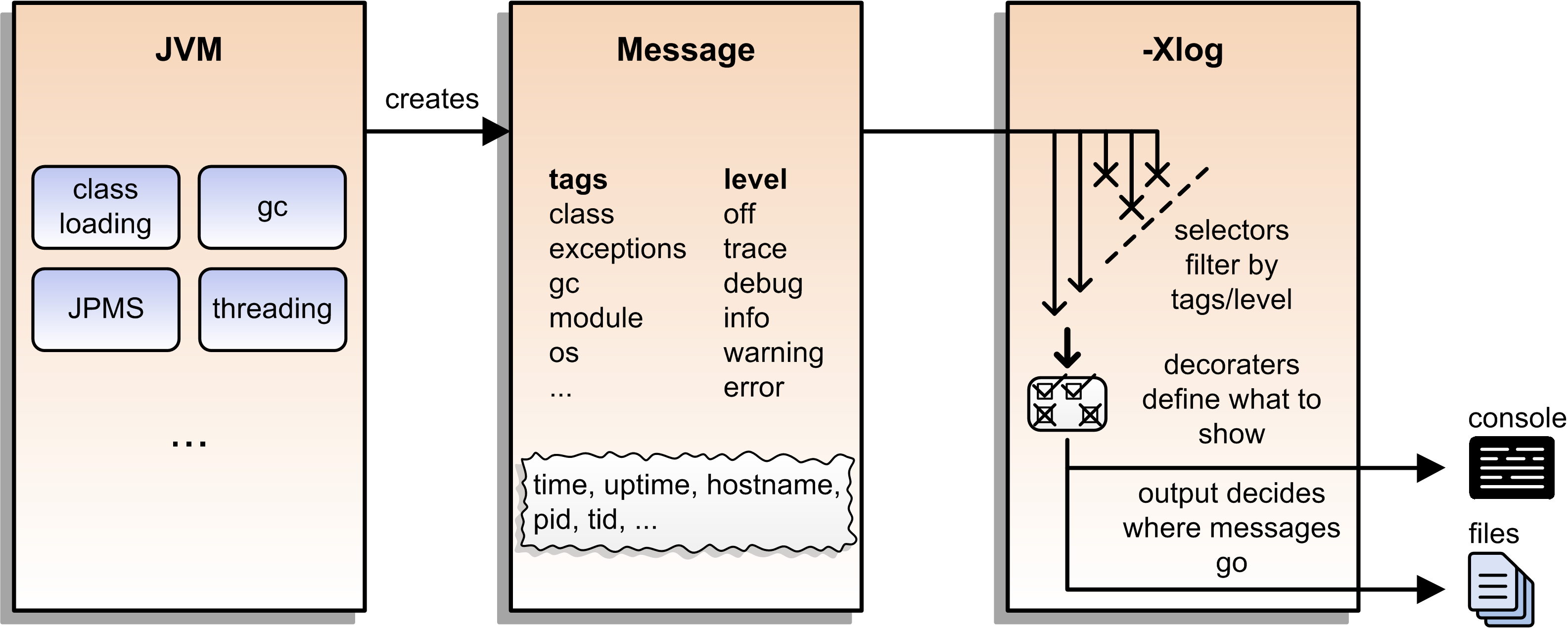
First Try
Plain use of -Xlog:
$ java -Xlog -version
# truncated a few messages
> [0.002s][info][os ] HotSpot is running ...
# truncated a lot of messagesYou can see:
JVM uptime (2ms)
log level (
info)tags (
os)message
Configuring -Xlog
This can be configured:
which messages to show
where messages go
what messages should say
How? -Xlog:help lists all options.
Which Messages?
Configure with selectors: $TAG_SET=$LEVEL:
# "exactly gc" on "warning"
-Xlog:gc=warning
# "including gc" on "warning"
-Xlog:gc*=warning
# "exactly gc and os" on "debug"
-Xlog:gc+os=debug
# "gc" on "debug" and "os" on warning
-Xlog:gc=debug,os=warningDefaults:
-Xlog # the same as -Xlog:all
-Xlog:$TAG # same as -Xlog:$TAG=infoWhere Do Messages Go?
Three possible locations:
stdout(default)stderrfile=$FILENAME
(file rotation is possible)
Example:
# all debug messages into application.log
-Xlog:all=debug:file=application.logWhich Information?
Decorators define what is shown:
time: time and date (also in ms and ns)uptime: time since JVM start (also in ms and ns)pid: process identifiertid: thread identifierlevel: log leveltags: tag-set
Example:
# show uptime in ms and level
-Xlog:all:stdout:level,uptimemillisPut Together
Formal syntax:
-Xlog:$SELECTORS:$OUTPUT:$DECORATORS:$OUTPUT_OPTS$SELECTORSare pairs of tag sets and log levels
(the docs call this what-expression)$OUTPUTisstdout,stderr, orfile=<filename>$DECORATORSdefine what is shown$OUTPUT_OPTSconfigure file rotation
Elements have to be defined from left to right.
(But can be empty, e.g. -Xlog::stderr.)
JVM Features
| Helpful NPEs ⑭ |
| Launch Source File ⑪ |
| Unified Logging ⑨ |
| Multi-Release JARs ⑨ |
| Redirected Platform Logging ⑨ |
"Do this on Java X, do that on Java Y."
Version Dependence
Main calls Version:
public class Main {
public static void main(String[] args) {
System.out.println(new Version().get());
}
}Version Dependence
Version exists twice:
public class Version {
public String get() { return "Java 8"; }
}
public class Version {
public String get() { return "Java 9+"; }
}(Btw, IDEs hate this!)
Creating A Multi‑Release JAR
Now, here’s the magic:
compile
MainandVersion[8]toout/java-8compile
Version[9]toout/java-9use new
jarflag--release:jar --create --file out/mr.jar -C out/java-8 . --release 9 -C out/java-9 .
JAR Content
└ dev
└ nipafx ... (moar folders)
├ Main.class
└ Version.class # 8
└ META-INF
└ versions
└ 9
└ dev
└ nipafx ... (moar folders)
└ Version.class # 9Run!
With java -cp out/mr.jar …Main:
prints
"Java 8"on Java 8prints
"Java 9+"on Java 9 and later
Great Success!
JVM Features
| Helpful NPEs ⑭ |
| Launch Source File ⑪ |
| Unified Logging ⑨ |
| Multi-Release JARs ⑨ |
| Redirected Platform Logging ⑨ |
Use your logging framework of choice
as backend for JDK logging.
Loggers and Finders
New logging infrastructure for the core libraries
(i.e. this does not apply to JVM log messages!)
new interface
System.Loggerused by JDK classes
instances created by
System.LoggerFinder
The interesting bit:
LoggerFinder is a service!
Creating a Logger
public class SystemOutLogger implements Logger {
public String getName() { return "SystemOut"; }
public boolean isLoggable(Level level) { return true; }
public void log(
Level level, ResourceBundle bundle,
String format, Object... params) {
System.out.println(/* ...*/);
}
// another, similar `log` method
}Creating a LoggerFinder
public class SystemOutLoggerFinder
extends LoggerFinder {
public Logger getLogger(
String name, Module module) {
return new SystemOutLogger();
}
}Registering the Service
Module descriptor for system.out.logger:
module system.out.logger {
provides java.lang.System.LoggerFinder
with system.out.logger.SystemOutLoggerFinder;
}Module system and JDK take care of the rest!
A Mixed Bag Of New JVM Features
In Java 9:
A Mixed Bag Of New JVM Features
In Java 10:
alternative memory device support (JEP 316)
In Java 11:
A Mixed Bag Of New JVM Features
In Java 12:
constants API (JEP 334)
HmacPBE (JDK-8215450)
finer PKCS12 KeyStore config (JDK-8076190)
In Java 14:
packaging tool (JEP 343)
In Java 15:
Nashorn was removed (JEP 372)
Performance
| Application Class-Data Sharing ⑩⑫⑬ |
| Compact Strings ⑨ |
| Indified String Concatenation ⑨ |
Performance
| Application Class-Data Sharing ⑩⑫⑬ |
| Compact Strings ⑨ |
| Indified String Concatenation ⑨ |
Improving application launch times.
Class-Data
JVM steps to execute a class’s bytecode:
looks up class in JAR
loads bytecode
verifies bytecode
stores class-data in
internal data structure
This takes quite some time.
If classes don’t change, the resulting
class-data is always the same!
Class-Data Sharing
Idea behind class-data sharing:
create class-data once
dump it into an archive
reuse the archive in future launches
(file is mapped into memory)
Effects
My experiments with a large desktop app
(focusing on classes required for launch):
archive has 250 MB for ~24k classes
launch time reduced from 15s to 12s
Bonus: Archive can be shared across JVMs.
Class-Data Sharing
Two variants:
- CDS
just for JDK classes
- AppCDS
JDK + application classes
CDS - Step #1
Create JDK archive on Java 10/11:
# possibly as root
java -Xshare:dumpJava 12+ downloads include
CDS archive for JDK classes.
CDS - Step #2
Use the archive:
$ java
-Xshare:on
# [... class path for app and deps ...]
org.example.MainIf archive is missing or faulty:
-Xshare:onfails fast-Xshare:auto(default) ignores archive
(Slides rely on default, i.e. no -Xshare.)
AppCDS
Create an AppCDS archive:
manually on Java 10+
dynamically on Java 13+
First manually, then dynamically.
AppCDS - Step #0
To manually create an AppCDS archive,
first create a list of classes
$ java
-XX:DumpLoadedClassList=classes.lst
# [... class path for app and deps ...]
org.example.MainThen, classes.lst contains
slash-separated names of loaded classes.
AppCDS - Step #1
Use the list to create the archive:
$ java
-Xshare:dump
-XX:SharedClassListFile=classes.lst
-XX:SharedArchiveFile=app-cds.jsa
# [... class path for app and deps ...]Creates archive app-cds.jsa.
AppCDS - Step #2
Use the archive:
$ java
-XX:SharedArchiveFile=app-cds.jsa
# [... class path for app and deps ...]
org.example.MainDynamic AppCDS
Java 13 can create archive when
program exits (without crash):
steps #0 and #1 are replaced by:
$ java -XX:ArchiveClassesAtExit=dyn-cds.jsa # [... class path for app and deps ...] org.example.Mainstep #2 as before:
$ java -XX:SharedArchiveFile=app-cds.jsa # [... class path for app and deps ...] org.example.Main
Dynamic AppCDS
The dynamic archive:
builds on the JDK-archive
contains all loaded app/lib classes
including those loaded by
user-defined class loaders
Heed The Class Path
What are the two biggest challenges
in software development?
naming
cache invalidation
off-by-one errors
Heed The Class Path
The archive is a cache!
It’s invalid when:
a JAR is updated
class path is reordered
a JAR is added
(unless when appended)
Heed The Class Path
To invalidate the archive:
during creation:
Java stores used class path in archive
class path may not contain wild cards
class path may not contain exploded JARs
when used:
Java checks whether stored path
is prefix of current path
Module Path?
Class path, class path…
what about the module path?
In this release, CDS cannot archive classes from user-defined modules (such as those specified in
--module-path). We plan to add that support in a future release.
— JEP 310
More On (App)CDS
For more, read this article:
tiny.cc/app-cds
Observe sharing with
-Xlog:class+load
(unified logging)
Performance
| Application Class-Data Sharing ⑩⑫⑬ |
| Compact Strings ⑨ |
| Indified String Concatenation ⑨ |
Going from UTF-16 to ISO-8859-1.
Strings and memory
20% - 30% of heap are
char[]forStringa
charis UTF-16 code unit ⇝ 2 bytesmost strings only require ISO-8859-1 ⇝ 1 byte
10% - 15% of memory is wasted!
Compact Strings
For Java 9, String was changed:
uses
byte[]instead ofchar[]bytes per character:
1 if all characters are ISO-8859-1
2 otherwise
Only possible because String makes
defensive copies of all arguments.
Performance
Simple benchmark:
(by Aleksey Shipilëv)
String method = generateString(size);
public String work() {
return "Calling method \"" + method + "\"";
}Depending on circumstances:
throughput 1.4x
garbage less 1.85x
More
Background on String
performance improvements:
Performance
| Application Class-Data Sharing ⑩⑫⑬ |
| Compact Strings ⑨ |
| Indified String Concatenation ⑨ |
"Improving" + "String" + "Concatenation"
String Concatenation
What happens when you run:
String s = greeting + ", " + place + "!";bytecode uses
StringBuilderJIT may (!) recognize and optimize
by writing content directly to newbyte[]breaks down quickly
(e.g. withlongordouble)
Why Not Create Better Bytecode?
new optimizations create new bytecode
new optimizations require recompile
test matrix JVMs vs bytecodes explodes
Why Not Call String::concat?
There is no such method.
concat(String… args)requirestoStringconcat(Object… args)requires boxing
Nothing fancy can be done
because compiler must use public API.
Invokedynamic
Invokedynamic came in Java 7:
compiler creates a recipe
runtime has to process it
defers decisions from compiler to runtime
(Used for lambda expressions and in Nashorn.)
Indy To The Rescue
With Indy compiler can express
"concat these things"
(without boxing!)
JVM executes by writing content
directly to new byte[].
Performance
Depending on circumstances:
throughput 2.6x
garbage less 3.4x
(Benchmarks by Aleksey Shipilëv)
Performance Of Indified Compact String Concat
Depending on circumstances:
throughput 2.9x
garbage less 6.4x
(Benchmarks by Aleksey Shipilëv)
More
Background on String
performance improvements:
A Mixed Bag Of Performance
In Java 9:
A Mixed Bag Of Performance
In Java 10:
A Mixed Bag Of Performance
In Java 11:
A Mixed Bag Of Performance
In Java 12:
A Mixed Bag Of Performance
In Java 13:
Shenandoah improvements:
internals (JDK-8221766, JDK-8224584)
more platforms (JDK-8225048, JDK-8223767)
ZGC improvements:
implements
-XX:SoftMaxHeapSize(JDK-8222145)max heap size of 16 TB (JDK-8221786)
uncommits unused memory (JEP 351)
A Mixed Bag Of Performance
In Java 14:
JFR event streaming API (JEP 349)
Shenadoah, G1, ZGC improvements
About Nicolai Parlog

Follow
More
Slides at slides.nipafx.dev
⇜ Get my book!
Hire me as a trainer
(Java 8+, JUnit 5)