
interface Node { }
record Number(long number) implements Node { }
record Negate(Node node) implements Node { }
record Absolute(Node node) implements Node { }
record Add(List<Node> summands) implements Node { }Java Next!
From Amber to Loom, from Panama to Valhalla
Lots to talk about!
| Project Amber |
| Project Panama |
| Project Valhalla |
| Project Loom |
Slides at slides.nipafx.dev.
Project Amber
Smaller, productivity-oriented Java language features
Profile:
project / wiki / mailing list
launched March 2017
led by Brian Goetz
Motivation
Some downsides of Java:
can be cumbersome
tends to require boilerplate
situational lack of expressiveness
Amber continuously improves that situation.
Delivered
Delivered
Pattern matching:
switch expressions
type pattern matching
sealed types
records
Misc:
vartext blocks
Pattern matching example
Evaluating simple arithmetic expressions.
1 + (-2) + |3 + (-4)|
Pattern matching example
Evaluating simple arithmetic expressions.
1 + (-2) + |3 + (-4)|
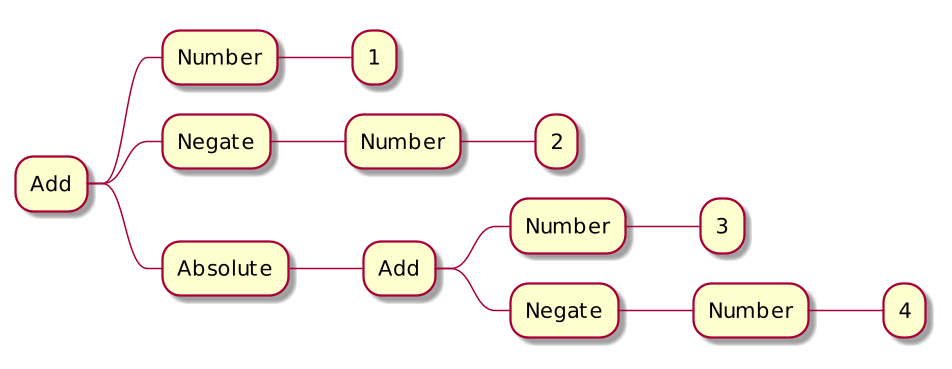
Polymorphism
Canonical way to apply operations
to a type hierarchy:
Polymorphism
Polymorphic solution
interface Node {
long evaluate();
}
record Number(long number) implements Node {
long evaluate() {
return number;
}
}
record Negate(Node node) implements Node {
long evaluate() {
return -node.evaluate();
}
}Polymorphic solution
record Absolute(Node node) implements Node {
long evaluate() {
long result = node.evaluate();
return result < 0 ? -result : result;
}
}
record Add(List<Node> summands) implements Node {
long evaluate() {
return summands.stream()
.mapToLong(Node::evaluate)
.sum();
}
}Domain overload
Should you implement evaluate this way?
Probably.
But what about:
Resources estimateResourceUsage()Strategy createComputationStrategy()Invoice createInvoice(User user)String prettyPrint()(like here)void draw(Direction d, Style s, Canvas c)
⇝ Central abstractions can be overburdened.
Visitor pattern
Separating a hierarchy from operations
is a case for the visitor pattern.
Alternative: pattern matching over sealed types.
Pattern matching solution
Seal type hierarchy:
sealed interface Node
permits Number, Negate, Absolute, Add { }
record Number(long number) implements Node { }
record Negate(Node node) implements Node { }
record Absolute(Node node) implements Node { }
record Add(List<Node> summands) implements Node { }Pattern matching now
Use type patterns in switch (JEP 420 / 2nd preview in 18):
long evaluate(Node node) {
return switch (node) {
case Number no -> no.number();
case Negate neg -> -evaluate(neg.node());
case Absolute abs && evaluate(abs.node()) < 0
-> -evaluate(abs.node());
case Absolute abs -> evaluate(abs.node());
case Add add -> add
.summands().stream()
.mapToLong(this::evaluate)
.sum();
// no default branch needed
};
}Pattern matching later
Also use deconstruction patterns (JEP 405 / not targeted):
long evaluate(Node node) {
return switch (node) {
case Number(long no) -> no;
case Negate(var n) -> -evaluate(n);
case Absolute(var n) && evaluate(n) < 0
-> -evaluate(n);
case Absolute(var n) -> evaluate(n);
case Add(var summands) -> summands.stream()
.mapToLong(this::evaluate)
.sum();
// no default branch needed
};
}Data-oriented programming
records + sealed types + patterns = data-oriented programming
In Data Oriented programming, we model our domain using data collections, that consist of immutable data. We manipulate the data via functions that could work with any data collection.
What is Data Oriented Programming?
— Yehonathan Sharvit
— Yehonathan Sharvit
Another use case
When parsing outside data,
types are often general
(think JsonNode).
Consider pattern matching
to tease apart the data.
Other Amber endeavors
Possible future changes:
template strings (white paper)
concise method bodies (JEP draft)
serialization revamp (white paper)
Project Amber
makes Java more expressive
reduces amount of code
makes us more productive
Timeline
My personal (!) guesses (!!):
- 2023
patterns in switch finalized
deconstruction patterns preview
template strings preview
- 2024
more patterns preview
Deeper Dives
🎥 Java Language Futures: All Aboard Project Amber
(Nov 2017)🎥 Java Language Futures: Late 2021 Edition (Sep 2021)
🎥 Pattern Matching in Java (17) (Sep 2021)
🎥 State of Pattern Matching with Brian Goetz (Feb 2022)
Project Panama
Interconnecting JVM and native code
Profile:
launched July 2014
led by Maurizio Cimadamore
Subprojects
vector API
foreign memory API
foreign function API
Vectorization
Given two float arrays a and b,
compute c = - (a² + b²):
void compute(float[] a, float[] b, float[] c) {
for (int i = 0; i < a.length; i++) {
c[i] = (a[i] * a[i] + b[i] * b[i]) * -1.0f;
}
}Auto-vectorization
Vectorization - modern CPUs:
have multi-word registers (e.g. 512 bit)
can store several numbers (e.g. 16
floats)can execute several computations at once
⇝ Single Instruction, multiple data (SIMD)
Just-in-time compiler tries to vectorize loops.
⇝ Auto-vectorization
Works but isn’t reliable.
Vector API
static final VectorSpecies<Float> VS =
FloatVector.SPECIES_PREFERRED;
void compute(float[] a, float[] b, float[] c) {
int upperBound = VS.loopBound(a.length);
for (i = 0; i < upperBound; i += VS.length()) {
var va = FloatVector.fromArray(VS, a, i);
var vb = FloatVector.fromArray(VS, b, i);
var vc = va.mul(va)
.add(vb.mul(vb))
.neg();
vc.intoArray(c, i);
}
}Vector API
Properties:
clear and concise API (given the requirements)
platform agnostic
reliable run-time compilation and performance
graceful degradation
Foreign APIs
Storing data off-heap is tough:
ByteBufferis limited (2GB) and inefficientUnsafeis… unsafe and not supported
JNI isn’t ideal:
involves several tedious artifacts (header file, impl, …)
can only interoperate with languages that align
with OS/architecture the JVM was built fordoesn’t reconcile Java/C type systems
Foreign-memory API
Safe and performant foreign-memory API:
to allocate:
MemorySegment,MemoryAddress,SegmentAllocatorto access/manipulate:
MemoryLayout,VarHandlecontrol (de)allocation:
MemorySession
Foreign-function API
Streamlined tooling/API for foreign functions
based on method handles:
classes to call foreign functions
CLinker,FunctionDescriptor,NativeSymboljextract: generates method handles from header file
Timeline
Official plans:
- JDK 19 (2022)
foreign function/memory API previews (JEP 424)
Vector API needs to wait for Valhalla’s
primitive types and universal generics.
Deeper Dives
Vector APIs:
Deeper Dives
Foreign APIs:
📝 design documents
🎥 Panama Update with Maurizio Cimadamore (Jul 2019)
🎥 ByteBuffers are dead, long live ByteBuffers! (Feb 2020)
🎥 The State of Project Panama with Maurizio Cimadamore (Jun 2021)
Project Valhalla
Advanced Java VM and Language feature candidates
Profile:
launched July 2014
led by Brian Goetz and John Rose
Motivation
Java has a split type system:
primitives
classes
Primitives
Potential downsides:
no class-building techniques
no custom primitives
can’t use with generics
Forced move in 90s to allow for
acceptable numeric performance.
Classes
Potential downsides:
mutable by default
memory access indirection
extra memory for header
allow locking and other
identity-based operations
Root cause
All custom types come with identity:
mutability
layout polymorphism
equalbut!=synchronization
etc.
All custom types come as references:
nullability
protect from tearing
But not all custom types need that!
Project Valhalla
Valhalla’s goals is to unify the type system:
value types (disavow identity)
primitive types (disavow references)
universal generics (
ArrayList<int>)specialized generics (backed by
int[])
Value types
value class RationalNumber {
private long nominator;
private long denominator;
// constructor, etc.
}Codes (almost) like a class - exceptions:
class and fields are implcitly final
superclasses are limited
Value type behavior
No identity:
some runtime operations
(e.g. synchronization)
throw exceptions==compares by state
References:
nullis default valueno tearing
Value type benefits
guaranteed immutability
more expressiveness
more optimizations
Migration to value types
The JDK (as well as other libraries) has many value-based classes, such as
OptionalandLocalDateTime. […] We plan to migrate many value-based classes in the JDK to value classes.
Primitive types
primitive class ComplexNumber {
private long rational;
private long irratoinal;
// constructor, etc.
}Codes (almost) like a value class - exception:
no field of own type
(i.e. no circularity)
Primitive type behavior
No identity (like value types).
No references:
default value has all fields set to their defaults
can tear under concurrent assignment
Benefit:
performance comparable to that of today’s primitives!
Primitive "boxes"
Sometimes, even int needs to be a reference:
nullability
non-tearability
self-reference
So we box to Integer.
What about ComplexNumber?
Primitive "boxes"
Each primitive class P declares two types:
P: as discussed so farP.ref: behaves like a value type
primitive class Node<T> {
T value;
Node.ref<T> nextNode;
}Migration to primitive types
[W]e want to adjust the basic primitives (
int,double, etc.) to behave as consistently with new primitives as possible.
On the example of int/Integer:
declare
intas primitive classalias
Integerwithint.refremove
Integer
Universal generics
When everybody creates their own values and primitives,
boxing becomes omni-present and very painful!
Universal generics allow value/primitive
classes as type parameters:
List<long> ids = new ArrayList<>();
List<RationalNumber> numbers = new ArrayList<>();Specialized generics
Healing the rift in the type system is great!
But if ArrayList<int> is backed by Object[],
it will still be avoided in many cases.
Specialized generics will fix that:
Generics over primitives will avoid references!
Project Valhalla
Value and primitive types plus
universal and specialized generics:
fewer trade-offs between
design and performanceno more manual specializations
better performance
can express design more clearly
more robust APIs
Makes Java more expressive and performant.
Timeline
Deeper Dives
📝 State of Valhalla
🎥 The State of Project Valhalla with Brian Goetz (Aug 2021)
🎥 Valhalla Update with Brian Goetz (Jul 2019)
Ad break
There’s much more going on!
APIs
Continuous improvements
Continuous improvements
Performance:
Security:
context-specific deserialization filters ⑰ (JEP 415)
Edwards-Curve Digital Signature Algorithm ⑮ (JEP 339)
ongoing enhancements (Sean Mullan’s blog)
Cleaning house
Migrations
To ease migrations:
stick to supported APIs
stick to standardized behavior
stick to well-maintained projects
keep dependencies and tools up to date
stay ahead of removals (
jdeprscan)build on each release (including EA)
Then you, too, can enjoy these projects ASAP!
Adoption
Java 11 is slowly but resolutely overtakes Java 8
adoption of 17 (from 11) looks good
always using latest is uncommon but persistent
Project Loom
JVM features and APIs for supporting easy-to-use, high-throughput, lightweight concurrency and new programming models
Profile:
launched January 2018
led by Ron Pressler
Motivation
Imagine a hypothetical HTTP request:
interpret request
query database (blocks)
process data for response
JVM resource utilization:
good for 1. and 3.
really bad for 2.
How to implement that request?
Synchronous
Align application’s unit of concurrency (request)
with Java’s unit of concurrency (thread):
use thread per request
simple to write, debug, profile
blocks threads on certain calls
limited number of platform threads
⇝ bad resource utilization
⇝ low throughput
Asynchronous
Only use threads for actual computations:
use non-blocking APIs
(with futures / reactive streams)harder to write, challenging to debug/profile
incompatible with synchronous code
shares platform threads
⇝ great resource utilization
⇝ high throughput
Motivation
Resolve the conflict between:
simplicity
throughput
Enter virtual threads!
A virtual thread:
is a regular
Threadlow memory footprint ([k]bytes)
small switching cost
scheduled by the Java runtime
Virtual thread management
The JVM manages virtual threads:
runs them on a pool of carrier threads
makes them yield on blocking calls
(frees the carrier thread!)continues them when calls return
Virtual thread example
Remember the hypothetical request:
interpret request
query database (blocks)
process data for response
In a virtual thread:
JVM submits task to carrier thread pool
when 2. blocks, virtual thread yields
JVM hands carrier thread back to pool
when 2. unblocks, JVM resubmits task
virtual thread continues with 3.
Example
try (var executor = Executors
.newVirtualThreadPerTaskExecutor()) {
IntStream
.range(0, 10_000)
.forEach(number -> {
executor.submit(() -> {
Thread.sleep(Duration.ofSeconds(1));
return number;
});
});
} // executor.close() is called implicitly, and waitsExample
void handle(Request request, Response response)
throws InterruptedException {
try (var executor = Executors
.newVirtualThreadPerTaskExecutor()) {
var futureA = executor.submit(this::taskA);
var futureB = executor.submit(this::taskB);
response.send(futureA.get() + futureB.get());
} catch (ExecutionException ex) {
response.fail(ex);
}
}Performance
Virtual threads aren’t "faster threads":
Each task takes the same time (same latency).
So why bother?
Parallelism vs concurrency
| Parallelism | Concurrency | |
|---|---|---|
Task origin | solution | problem |
Control | developer | environment |
Resource use | coordinated | competitive |
Metric | latency | throughput |
Abstraction | CPU cores | tasks |
# of threads | # of cores | # of tasks |
Performance
When workload is not CPU-bound:
start waiting as early as possible
for as many tasks as possible
⇝ Virtual threads increase throughput:
when number of concurrent tasks is high
when workload is not CPU-bound
Use Cases
Virtual threads are cheap and plentiful:
no pooling necessary
allows thread per task
allows liberal creation
of threads for subtasks
⇝ Enables new concurrency programming models.
Structured concurrency
Structured programming:
prescribes single entry point
and clearly defined exit pointsinfluenced languages and runtimes
Simlarly, structured concurrency prescribes:
When the flow of execution splits into multiple concurrent flows, they rejoin in the same code block.
Structured concurrency
When the flow of execution splits into multiple concurrent flows, they rejoin in the same code block.
⇝ Threads are short-lived:
start when task begins
end on completion
⇝ Enables parent-child/sibling relationships
and logical grouping of threads.
Unstructured concurrency
void handle(Request request, Response response)
throws InterruptedException {
try (var executor = Executors
.newVirtualThreadPerTaskExecutor()) {
// what's the relationship between
// this and the two spawned threads?
// what happens when one of them fails?
var futureA = executor.submit(this::taskA);
var futureB = executor.submit(this::taskB);
// what if we only need the faster one?
response.send(futureA.get() + futureB.get());
} catch (ExecutionException ex) {
response.fail(ex);
}
}Structured concurrency
void handle(Request request, Response response)
throws InterruptedException {
// define explicit success/error handling
try (var scope = new StructuredTaskScope
.ShutdownOnFailure()) {
var futureA = scope.fork(this::taskA);
var futureB = scope.fork(this::taskB);
// wait explicitly until success criteria met
scope.join();
scope.throwIfFailed();
response.send(futureA.get() + futureB.get());
} catch (ExecutionException ex) {
response.fail(ex);
}
}Structured concurrency
forked tasks are children of the scope
creates relationship between threads
success/failure policy can be defined
across all children
Project Loom
Virtual threads:
code is simple to write, debug, profile
high throughput
new programing model
Structured concurrency:
clearer concurrency code
simpler failure/success policies
better debugging
Timeline
My personal (!) guesses (!!):
- JDK 19 (2022) / JDK 20 (2023)
virtual threads preview
structured concurrency API preview
- 2024
more structured concurrency APIs (?)
Deeper Dives
So long…

More
Slides at slides.nipafx.dev⇜ Get my book!
Follow Nicolai
nipafx.dev/nipafx
Follow Java
inside.java/java // /openjdk
{kind=link}