
Stream<User> parse(Stream<String> strings) {
// compile error:
// "Unhandled exception ParseException"
return strings.map(this::parse);
}
User parse(String userString) throws ParseException {
// ...
}25 Hours of Java
Stream Exception Handling
Setting the Scene
Which options do we have?
Try in Lambda
Stream<User> parse(Stream<String> strings) {
return strings
.map(string -> { try {
return parse(string);
} catch (ParseException ex) {
return null;
}})
.filter(Objects::nonNull);
}super ugly
requires extra clean-up step
handling exception locally can be hard
troublesome elements "disappear"
Try in Method
Stream<User> parse(Stream<String> strings) {
return strings
.map(this::tryParse)
.filter(Objects::nonNull);
}
private User tryParse(String string) {
try { return parse(string); }
catch (ParseException ex) { return null; }
}somewhat ugly
requires extra clean-up step ("far away")
handling exception locally can be hard
troublesome elements "disappear"
Sneaky Throws
How to "trick the compiler":
static Function<T, R> hideException(
CheckedFunction<T, R, Exception> function) {
return element -> {
try {
return function.apply(element);
} catch (Exception ex) {
return sneakyThrow(ex);
}
};
}
// sneakyThrow does shenanigans with generics
// and unchecked casts to "confuse the compiler"Sneaky Throws
Stream<User> parse(Stream<String> strings) {
return strings
.map(Util.hideException(this::parse));
}very surprising (hides a bomb in the stream!)
stream executor has to handle exception
can’t
try-catch(ParseException)because
checked exceptions need to be declaredexception aborts stream pipeline
Please never do that!
Wrap in Unchecked
Another Util method:
static Function<T, R> uncheckException(
CheckedFunction<T, R, Exception> function) {
return element -> {
try {
return function.apply(element);
} catch (Exception ex) {
// add special cases for RuntimeException,
// InterruptedException, etc.
throw new IllegalArgumentException(
element, ex);
}
};
}Wrap in Unchecked
Stream<User> parse(Stream<String> strings) {
return strings
.map(Util.uncheckException(this::parse));
}stream executor has to handle exception
exception aborts stream pipeline
Remove Trouble
Another Util method:
static Function<T, Optional<R>> wrapOptional(
CheckedFunction<T, R, Exception> function) {
return element -> {
try {
return Optional.of(
function.apply(element));
} catch (Exception ex) {
return Optional.empty();
}
};
}Remove Trouble
Stream<User> parse(Stream<String> strings) {
return strings
.map(Util.wrapOptional(this::parse))
// Java 9: .flatMap(Optional::stream)
.filter(Optional::isPresent)
.map(Optional::get);
}requires extra clean-up step
(at least supported by compiler)troublesome elements "disappear"
Expose With Try
Try<T> is similar to Optional:
has two states (error or success)
allows to process them with functions
parameterized in type of success result
Another Util method:
static Function<T, Try<R>> wrapTry(
CheckedFunction<T, R, Exception> function) {
return element -> Try.of(
() -> function.apply(element));
}Expose With Try
Stream<Try<User>> parse(Stream<String> strings) {
return strings
.map(Util.wrapTry(this::parse));
}requires external library (e.g. Vavr)
encodes possibility of failure in API
makes error available to caller
error is encoded as Exception/Throwable
Expose With Either
Either<L, R> is similar to Optional:
has two states (left or right)
allows to process them with functions
parameterized in types of left and right
if used for failure/success, exception goes left
(by convention)
Expose With Either
Another Util method:
static Function<T, Either<EX, R>> wrapEither(
CheckedFunction<T, R, EX> function) {
return element -> {
try {
return Either.right(
function.apply(element));
} catch (Exception ex) {
// add special cases for RuntimeException,
// InterruptedException, etc.
return Either.left((EX) ex);
}
};
}Expose With Either
Stream<Either<ParseException, User>> parse(
Stream<String> strings) {
return strings
.map(Util.wrapEither(this::parse));
}requires external library (e.g. Vavr)
encodes possibility of failure in API
makes error available to caller
error has correct type
Reflection on Exceptions
don’t be smart and "trick the compiler"
return a clean stream, no
null!ideally, use types to express possibility of failure
Streams don’t cooperate well with checked exceptions.
See that as a chance to use functional concepts
for greater good of code base!
Java Module System
Modules
Modules
have a unique name
express their dependencies
export specific packages
and hide the rest
These information
are defined in
module-info.javaget compiled to
module-info.classend up in JAR root folder
Readability
Modules express dependencies
with requires directives:
module A {
requires B;
}module system checks all dependencies
(⇝ reliable configuration)lets module read its dependencies
Accessibility
Modules export packages
with exports directives
module B {
exports p;
}Code in module A can only access Type in module B if:
Typeis publicTypeis in an exported packageA reads B
(⇝ strong encapsulation)
Jigsaw Advent Calendar
A simple example
Structure
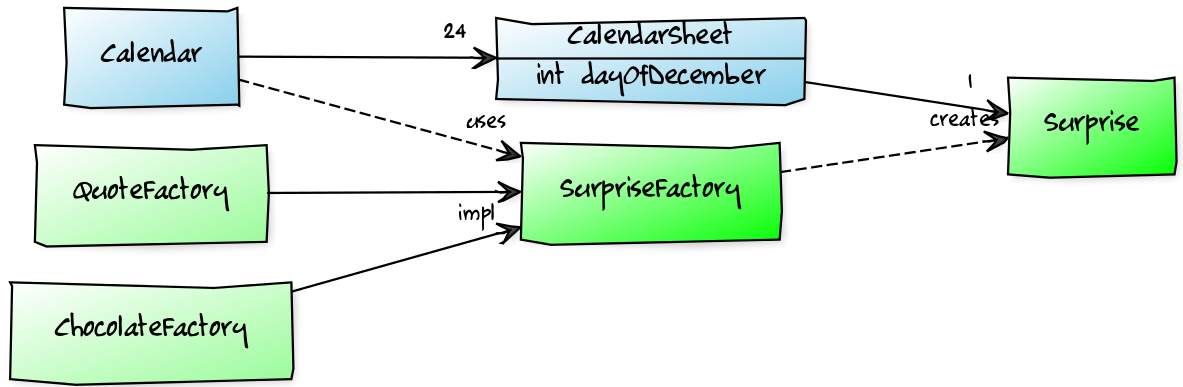
Code
public static void main(String[] args) {
List<SurpriseFactory> factories = List.of(
new ChocolateFactory(), new QuoteFactory());
Calendar cal = Calendar.create(factories);
System.out.println(cal.asText());
}Module Structure
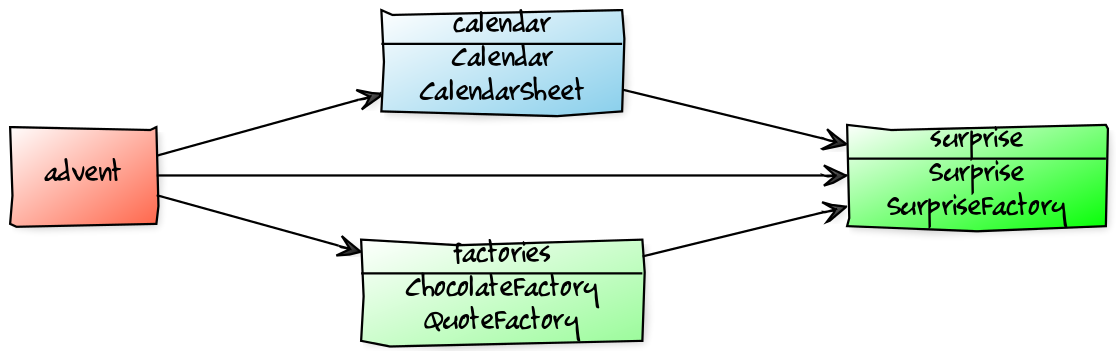
Module Structure
module surprise {
// requires no other modules
exports dev.nipafx.advent.surprise;
}module calendar {
requires surprise;
exports dev.nipafx.advent.calendar;
}module factories {
requires surprise;
exports dev.nipafx.advent.factories;
}module advent {
requires calendar;
requires factories;
requires surprise;
}Module Creation
Compilation, Packaging, Execution
# compile with module-info.java
$ javac -d classes ${*.java}
# package with module-info.class
# and specify main class
$ jar --create
--file mods/advent.jar
--main-class advent.Main
${*.class}
# run by specifying a module path
# and a module to run (by name)
$ java --module-path mods --module adventDependency Inversion?
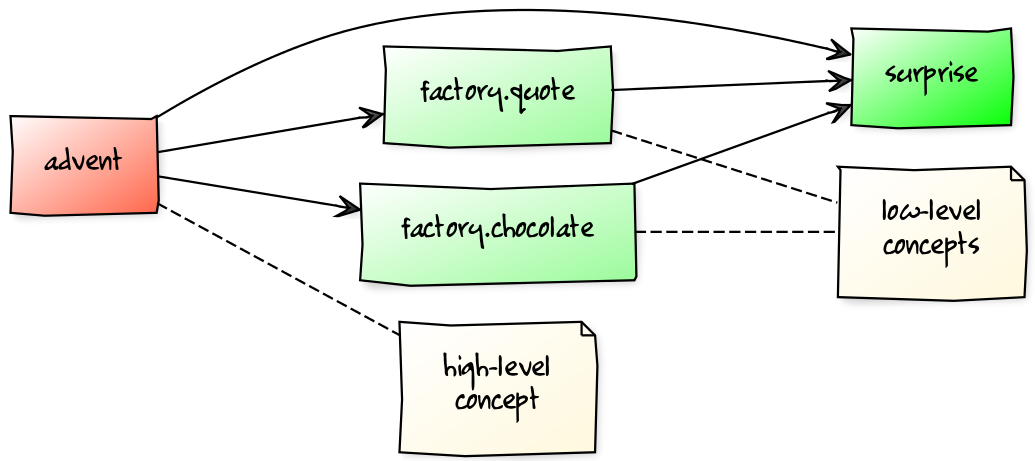
Service Locator Pattern
Consumers and implementations
of an API should be decoupled.
Service locator pattern:
service registry as central arbiter
implementors inform registry
consumers call registry to get implementations
Services and Modules
In the Java module system:
modules declare which services they use
modules declare which services they provide
ServiceLoaderis the registrycode can interact with it to load services
Service Declarations
Module declarations:
// consumer
module A {
uses some.Service;
}
// provider
module B {
provides some.Service
with some.Type;
}(A and B need access to some.Service)
Loading Services
A never "sees" providers like B
module system picks up all providers
A can get providers from
ServiceLoader
ServiceLoader.load(Service.class)Factory Services
module advent {
requires surprise;
uses surprise.SurpriseFactory;
}
module factory.chocolate {
requires surprise;
provides surprise.SurpriseFactory
with factory.chocolate.ChocolateFactory;
}
module factory.quote {
requires surprise;
provides surprise.SurpriseFactory
with factory.quote.QuoteFactory;
}Factory Services
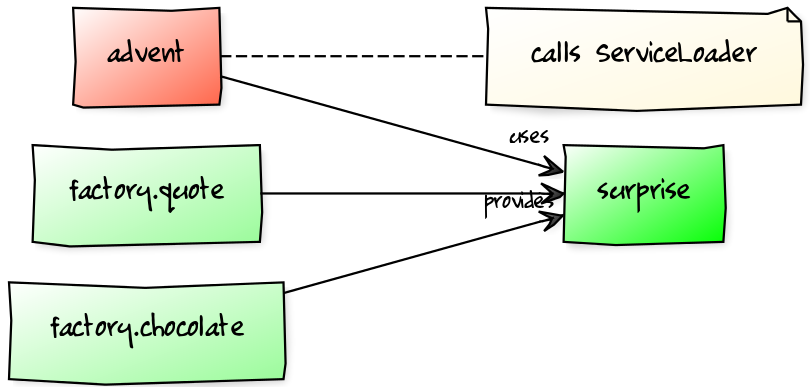
Factory Services
public static void main(String[] args) {
List<SurpriseFactory> factories = ServiceLoader
.load(SurpriseFactory.class).stream()
.map(Provider::get)
.collect(toList());
Calendar cal = Calendar.create(factories);
System.out.println(cal.asText());
}Summary
To decouple API consumers and providers:
consumer
uses Serviceprovider
provides Service with Impl
Module system is service locator;
request implementations from ServiceLoader:
ServiceLoader.load(Service.class)
Creating Runtime Images With JLink
Custom-Made For Your Application
Remember This?
Benefiting From JDK Modularization
Create a JDK install with just the code you need:
know which modules your app uses (⇝
jdeps)create an image with those modules (⇝
jlink)
This is about jlink.
A Minimal JDK Image
Create with jlink:
$ jlink
# define output folder for the image
--output jdk-minimal
# where to find modules? (obsolete in ⑪)
--module-path $JAVA_HOME/jmods
# which modules to add (includes dependencies!)
--add-modules java.baseTry it out:
$ jdk-minimal/bin/java --list-modules
> java.baseImage For A Backend
Say you use JAXP, JDBC, and JUL:
$ jlink
--output jdk-backend
--add-modules java.xml,java.sql,java.loggingImage For A Backend
$ jdk-backend/bin/java --list-modules
> java.base
> java.logging
> java.sql
> java.transaction.xa
> java.xmlImage Including Your App And Dependencies
To create an image for your app:
all JARs need to be modularized!
including dependencies
Unless you use Gunnar Morling’s ModiTect,
which creates module descriptors on the fly.
Linking And Launching
Creating the image:
$ jlink
--output app-image
--module-path $JAVA_HOME/jmods:mods
--add-modules advent
# services are not resolves automatically
--add-modules factory.surprise,factory.chocolateLaunching the app:
app-image/bin/java --module adventCreating A Launcher
You can even create a launcher:
$ jlink
--output app-image
--module-path $JAVA_HOME/jmods:mods
--add-modules advent,...
# --launcher <name>=<module>[/<mainclass>]
--launcher calendar=adventLaunching the app:
app-image/bin/calendarMore Features
automatic service binding
(with--bind-services)various optimizations
(size and launch performance)plugin API (not yet public)
cross OS image generation
Summary
You can use jlink to:
create a runtime image
with just the right modulescreate an application image
including your code
This should make certain kinds of deploys
smaller and easier.
JUnit 5 Extensions
Sources: github.com/nipafx/demo-junit-5
Extension points
Extensions in JUnit 4
Runners
Manage a test’s full lifecycle.
@RunWith(MockitoJUnitRunner.class)
public class MyTest { ... }very flexible
heavyweight
exclusive
Extensions in JUnit 4
Rules
Execute code before and after statements.
public class MyTest {
@Rule
public MockitoRule rule =
MockitoJUnit.rule();
}added in 4.7
lightweight
limited to before/after behavior
Extensions in JUnit 4
Extension model is not optimal:
two competing mechanisms
each with limitations
but with considerable overlap
composition can cause problems
Approaching extensions
From JUnit 5’s Core Principles:
Prefer extension points over features
Quite literally,
JUnit 5 has Extension Points
Extension points
instance post processor
template invocation
@BeforeAlland@BeforeEachexecution condition
parameter resolution
before test execution
after test execution
exception handling
@AfterEachand@AfterAll
Implementing extensions
one interface for each extension point
method arguments capture context
public interface BeforeEachCallback
extends Extension {
void beforeEach(ExtensionContext context);
}an extension can use multiple points
to implement its feature
Example extension
We want to benchmark our tests!
for each test method
write the elapsed time to console
How?
before test execution: store test launch time
after test execution: print elapsed time
Benchmark extension
public class BenchmarkExtension implements
BeforeTestExecutionCallback,
AfterTestExecutionCallback {
private long launchTime;
// ...
}Benchmark extension
@Override
public void beforeTestExecution( /*...*/ ) {
launchTime = currentTimeMillis();
}
@Override
public void afterTestExecution( /*...*/ ) {
printf("Test '%s' took %d ms.%n",
context.getDisplayName(),
currentTimeMillis() - launchTime);
}Other examples
Remember This?
@Test
@DisabledOnFriday
void failingTest() {
assertTrue(false);
}Let’s see how it works!
Disabled extension
public class DisabledOnFridayCondition
implements ExecutionCondition {
@Override
public ConditionEvaluationResult evaluate( /*...*/ ) {
if (isFriday())
return disabled("Weekend!");
else
return enabled("Fix it!");
}
}Other examples
What about parameter injection?
@Test
void someTest(MyServer server) {
// do something with `server`
}Parameter injection
public class MyServerParameterResolver
implements ParameterResolver {
@Override
public boolean supportsParameter(
ParameterContext pCtx, /*...*/) {
return MyServer.class
== pCtx.getParameter().getType();
}
@Override
public Object resolveParameter(
ParameterContext pCtx, /*...*/) {
return new MyServer();
}
}Extension points
Summary
Jupiter provides many extension points
each extension point is an interface
extensions implement various interfaces
implementations are called when
test execution reaches corresponding point
Extension context
Extension context
Quick look at ExtensionContext:
// every node has its own context
Optional<ExtensionContext> getParent();
ExtensionContext getRoot();
// some node-related info
String getUniqueId();
String getDisplayName();
Set<String> getTags();
// don't use System.out!
void publishReportEntry(String key, String value);
// configure your extension with system properties
Optional<String> getConfigurationParameter(String key)Extension context
Quick look at ExtensionContext:
// to reflect over the test class/method
Optional<AnnotatedElement> getElement();
Optional<Class<?>> getTestClass();
Optional<Method> getTestMethod();
Optional<Lifecycle> getTestInstanceLifecycle();
// use the store for extension state
Store getStore(Namespace namespace);Stateless extensions
JUnit makes no promises regarding
extension instance lifecycle.
⇝ Extensions must be stateless!
Use the Store, Luke:
namespaced
hierarchical
key-value
Extension store
Namespaced
Store is accessed via ExtensionContext
given a Namespace:
Store getStore(Namespace namespace);keeps extensions from stepping
on each other’s toescould allow deliberate communication 🤔
Extension store
Hierarchical
Reads from the store forward to parent stores:
method store ⇝ class store
nested class store ⇝ surrounding class store
Writes always go to the called store.
Extension store
Key-Value
The store is essentially a map:
Object getObject(Object key);
Object getOrComputeIfAbsent(
K key, Function creator);
void put(Object key, Object value)
Object remove(Object key)Overloads with type tokens exist.
Stateless benchmark
void storeNowAsLaunchTime(
ExtensionContext context) {
long now = currentTimeMillis();
context.getStore(NAMESPACE)
.put(KEY, now);
}
long loadLaunchTime(
ExtensionContext context) {
return context.getStore(NAMESPACE)
.get(KEY, long.class);
}Extension context
Summary
use
ExecutionContextto access
information about the test, e.g.
parents, tags, test class/methoduse
Storeto be stateless
Registering extensions
Three ways…
Three ways to register extensions:
declaratively with
@ExtendWithprogrammatically with
@RegisterExtensionautomatically with service loader
Declaratively
Use @ExtendWith to register extension
with annotation:
@ExtendWith(DisabledOnFridayCondition.class)
class SomeTest {
...
}That’s technical and verbose… :(
Declaratively
Meta-annotations to the rescue!
JUnit 5’s annotations are meta-annotations
JUnit 5 checks recursively for annotations
⇝ We can create our own annotations!
Creating annotations
@ExtendWith(DisabledOnFridayCondition.class)
public @interface DisabledOnFriday { }
@Test
@Tag("integration")
@ExtendWith(BenchmarkExtension.class)
@ExtendWith(MyServerParameterResolver.class)
public @interface IntegrationTest { }
@IntegrationTest
@DisabledOnFriday
void testLogin(MyServer server) { ... }Programmatically
Annotations only accept compile-time constants:
@DisabledByFormula(
"After Mayan b'ak'tun 13",
// Nope 😩
now().isAfter(MAYAN_B_AK_TUN_13))
class DisabledByFormulaTest {
private static final LocalDateTime
MAYAN_B_AK_TUN_13 = of(2012, 12, 21, 0, 0);
}Programmatically
Instead declare extension as field
and annotate with @RegisterExtension:
class DisabledByFormulaTest {
private static final LocalDateTime
MAYAN_B_AK_TUN_13 = of(2012, 12, 21, 0, 0);
@RegisterExtension
static DisabledByFormula FORMULA = disabledWhen(
"After Mayan b'ak'tun 13",
now().isAfter(MAYAN_B_AK_TUN_13));
}Automatically
You can use Java’s service loader
to register extensions globally,
(i.e. without putting them into code)
but I won’t go into it here.
Registering extensions
Summary
Extensions can be registered in three ways:
declaratively with
@ExtendWithprogrammatically with
@RegisterExtensionautomatically with service loader
Releases, Licenses, Support
The new world
OpenJDK is the default
(not Oracle JDK)major release every 6 months
(not every 2-5 years)only selected versions get LTS
(not all of them)
What’s OpenJDK?
OpenJDK is Java’s reference implementation:
a project
a code base
It doesn’t ship binaries, but others do:
Oracle on jdk.java.net
AdoptOpenJDK on adoptopenjdk.net
OpenJDK vs Oracle JDK
Sun/Oracle JDK used to…
contain more features
be perceived as more stable
be perceived as more performant
As of Java 11, on a technical basis,
Oracle JDK and OpenJDK are identical.
*
OpenJDK vs Oracle JDK
Only difference is license and support model:
Oracle’s OpenJDK: licensed under GPL+CE
Oracle JDK is fully commercial:
from 11 on, no free use in production
⇝ OpenJDK is the new default!
(Java is still free)
(More on support later…)
More releases?
The old plan:
releases are driven by flagship features
new major release roughly every 2 years
The old reality:
Java 7 took 5 years
Java 8 took 3 years
Java 9 took 3.5 years
"Bump an 'almost ready' feature
2+ years into the future?"
⇝ "Better to delay the release."
Downsides
implemented features provide no value
increases reaction time
puts (political) pressure on projects
makes everybody grumpy
More releases!
If it hurts, do it more often.
fixed six-month release cadence
(March and September)ship everything that is ready
All are major releases
with known quality guarantees.
⇝ No "beta versions"!
Upsides
completed features get out earlier
no pressure to complete features on time
easier to react to changes in the ecosystem
easier to incubate features
Incubate features?
Two concepts allow features to incubate:
Features are shipped for experimentation.
There are safeguards against accidental proliferation.
Release fatigue?
"Java will change too fast."
"Test matrix will explode."
"Ecosystem will fragment."
"Constant migrations will be expensive."
What is LTS?
To discuss long-term support,
lets look at JDK development:
there’s the OpenJDK code base at
hg.openjdk.org/jdk/jdk/there are many clones:
for each JDK release
for each JDK project
each vendor has their own
OpenJDK development
A new feature, simplified:
developed in "feature branch"
merged into "master" when (nearly) finished
A release, simplified:
"release branch" created 3 months prior
only bug fixes merged to "release branch"
A bug/security/etc fix, simplified:
usually developed in "master"
merged into relevant release branches
OpenJDK support
Support really means:
fixing bugs, usually in "master"
merging fixes to "release branches"
How does Oracle handle that?
work on "master" in OpenJDK
merge to current "release branch" in OpenJDK
merge to LTS version in Oracle JDK
Long-term support
What’s left for long-term support?
⇝ Merging fixes into old JDK versions.
Commercial LTS
Free LTS
Long-term support for OpenJDK:
commitment by the community:
4+ years for 8, 11, 17, 23, etc.for OpenJDK 8 until 06/2023
for OpenJDK 11 until 10/2024
built and shipped by Adopt OpenJDK
Free LTS
Staying on Java 11 LTS
I’d love for everyone
to always be up to date.
But:
Going from Java 11 to 12
is not without risks.
😢
Risks for Java 12-16
Lack of support for 12-16:
free support is very unlikely
commercial support is rare
(Azul offers MTS for 13 and 15)
Without support, you have to upgrade
to each major version immediately!
Risks for Java 12-16
What could possibly go wrong?!
Before you upgrade to Java 12:
read Should you adopt Java 12 […]?
by Stephen Colebournetake a coffee break
understand that most risks come
from building against 12be content that all you need
to upgrade is run on 12
Risks for Java 12-16
What could possibly go wrong?!
@Deprecated(forRemoval=true)changes to unsupported APIs, e.g.
Unsafe
Problems are not likely,
but usually hard to predict.
⇝ Chance is low.
Risks for Java 12-16
If an upgrade fails,
you have two choices:
run on an unsupported (unsecure) JVM 😮
downgrade to recent LTS 😱
⇝ Damage is potentially enormous.
Risks for Java 12-16
expected_damage = chance * damageConsider this:
more up-to-date ⇝ lower chance
fewer dependencies ⇝ lower chance
smaller code base ⇝ smaller damage
Advice
find a suitable upgrade cadence
build on each release (including EA)
only rely on standardized behavior
heed deprecation warnings (
jdeprscan)keep dependencies and tools up to date
Most importantly:
Be aware of what’s coming!
Amber, Valhalla, Loom, Leyden
Project Amber
Smaller, productivity-oriented Java language features
Profile:
led by Brian Goetz
project / wiki / mailing list / talks: 0, 1, 2 /
inofficial early access buildslaunched March 2017
Motivation
Java compared to more modern languages:
can be cumbersome
lacks expressiveness
tends to require boilerplate
Amber wants to improve that situation!
Delivered
Endeavors
pattern matching (JEP 305)
records (JEP 359)
sealed types (JEP 360)
serialization revamp (white paper)
concise method bodies (JEP draft)
raw string literals (maybe)
Pattern matching
Object value = // ...
String formatted = switch (value) {
case Integer i -> String.format("int %d", i);
case Byte b -> String.format("byte %d", b);
case Long l -> String.format("long %d", l);
case Double d -> String.format("double %f", d);
case String s -> String.format("String %s", s);
default -> "unknown " + value.toString();
};Yeah:
more powerful conditions
no repetition between condition and block
Pattern matching
public int eval(Node n) {
return switch(n) {
case IntNode(int i) -> i;
case NegNode(Node nn) -> -eval(nn);
case AddNode(Node left, Node right) ->
eval(left) + eval(right);
};
}Yeah:
deconstructing complex objects
goodbye visitor pattern!
Records
public record Range(int low, int high) {
// compiler generates:
// * constructor, deconstructor
// * equals/hashCode/toString
// * accessors low(), high()
}Yeah:
no boilerplate for plain "data carriers"
no room for error in
equals/hashCodemakes Java more expressive
Records
The API for a record models the state, the whole state, and nothing but the state.
The deal:
give up encapsulation
couple API to internal state
get API for free
Customized records
public record Range(int low, int high) {
// compiler knows signature and assigns to fields
public Range {
if (low > high)
throw new IllegalArgumentException();
}
public void setLow(int low) {
if (low > this.high)
throw new IllegalArgumentException();
this.low = low;
}
}Sealed types
Have a closer look at the cases:
public int eval(Node n) {
return switch(n) {
case IntNode(int i) -> // ...
case NegNode(Node n) -> // ...
case AddNode(Node left, Node right) -> // ...
};
}Why is there no default branch?
Sealed types
public sealed interface Node
permits IntNode, NegNode, AddNode {
// interface declaration
}Yeah:
code expresses intended subtypes
pattern matching can check completeness
Death to serialization!
Serialization is hell:
complicates every JDK feature
repeated security vulnerabilities
uses "invisible" mechanisms
The JDK team wants to get rid of it!
Serializing records
Replacement may look as follows:
only works with records
deconstructs a record graph
passes data to serialization engine
one engine per format:
XML, JSON, YAML, …
New serialization
Yeah:
records are a great fit for serialization
new mechanism uses (de)constructors
superior maintainability
Concise method bodies
class ListWrapper<E> implements List<E> {
private List<E> list;
public int size() -> list.size();
public T get(int index) -> list.get(index);
public int indexOf(E el) = list::indexOf;
}Yeah:
simple methods get simple code
fewer (empty) lines
Raw string literals
String regex = \"\+(\d*[.])?\d"Yeah:
no escaping of special characters
But:
was planned as preview in Java 12
removed last minute
Turns out, it’s complicated. 😁
Raw multi-line strings
Maybe?
String yaml = \"""
name: "Positive number"
regex: "\+(\d*[.])?\d"
""";Project Amber
Makes Java more expressive:
type inference with
var⑩switch expressions ⑫
text blocks ⑬
pattern matching
records
sealed types
serialization revamp
concise method bodies
raw string literals
Project Valhalla
Advanced Java VM and Language feature candidates
Profile:
led by Brian Goetz and John Rose
project / wiki / mailing list / talks: 0, 1, 2, 3 /
official early access buildslaunched July 2014
Motivation
In Java, (almost) everything is a class:
mutable by default
memory access indirection
requires extra memory for header
allows locking and other
identity-based operations
Wouldn’t it be nice to create a custom int?
Value types
public value Range {
// implicitly final
private int low;
private int high;
// you write:
// * constructor, static factories
// * equals/hashCode/toString
// * accessors, etc.
}Value types
public value Range {
private int low;
private int high;
}Yeah:
enforced immutability
no memory indirection! (flat)
no
Objectheader! (dense)makes Java more expressive
Value types
Codes like a class, works like an
int.
The deal:
give up identity / mutability
(and self references)get flat and dense memory layout
Values vs Records
Values
no identity / mutability
⇝ flat and dense memory layout
Records
no encapsulation
⇝ less boilerplate
Might be combinable to "value records".
Generic specialization
When everybody creates their own "primitives",
boxing becomes omni-present and very painful!
List<int> ids = new ArrayList<>();Yeah:
backed by an actual
int[]great performance
works with your value types
Put together
Value types and generic specialization together,
have immense effects inside the JDK!
no more manual specializations:
functional interfaces
stream API
OptionalAPI
better performance
Put together
Value types and generic specialization together,
have immense effects on your code!
fewer trade-offs between
design and performancebetter performance
can express design more clearly
more robust APIs
Project Valhalla
Makes Java more expressive and performant:
value types
primitive specialization
Project Loom
Motivation
Imagine a hypothetical request:
interpret request
query database (blocks)
process data for response
JVM resource utilization:
good for tasks 1., 3.
really bad for task 2.
How to implement that request?
Motivation
- Synchronous (simple)
thread per request
blocks on certain calls
bad thread utilization
- Asynchronous (not so simple)
use non-blocking APIs with futures
incompatible with synchronous code
great thread utilization (scalable!)
Enter fibers!
A fiber:
looks like a thread to devs
low memory footprint ([k]bytes)
small switching cost
scheduled by the JVM
Fiber management
The JVM manages fibers:
runs them in a pool of carrier threads
makes fibers yield on blocking calls
(frees the carrier thread!)continues fibers when calls return
Fiber example
Remember the hypothetical request:
interpret request
query database (blocks)
process data for response
In a fiber:
JVM submits fiber to thread pool
when 2. blocks, fiber yields
JVM hands thread back to pool
when 2. unblocks, JVM resubmits fiber
fiber continues with 3. (how?)
Fibers
Yeah:
great thread utilization
code is written/debugged as if synchronous
legacy code may be forward compatible
Continuations
How do fibers continue?
use continuations (low-level API)
JVM stores and restores call stack
Project Loom
Makes threading more pleasant:
simple programming model
great thread utilization
Project Leyden
Faster startup, shorter time to peak performance, smaller footprint
Profile:
led by Mark Reinhold
first discussed in April 2020
not yet officially launched
Java 9
Sources: github.com/nipafx/demo-java-x
Migration & Modularization
I recently did a stream on that:
twitch.tv/videos/614048355
TL;DR:
update all the things
cross fingers
Private Interface Methods
Enabling reuse between default methods.
No Reuse
public interface InJava8 {
default boolean evenSum(int... numbers) {
return sum(numbers) % 2 == 0;
}
default boolean oddSum(int... numbers) {
return sum(numbers) % 2 == 1;
}
default int sum(int[] numbers) {
return IntStream.of(numbers).sum();
}
}Private Methods
public interface InJava9 {
private int sum(int[] numbers) {
return IntStream.of(numbers).sum();
}
}Just like private methods in abstract classes:
must be implemented
can not be overriden
can only be called in same source file
Try-With-Resources
Making try-with-resources blocks cleaner.
Useless Variable
void doSomethingWith(Connection connection)
throws Exception {
try (Connection c = connection) {
c.doSomething();
}
}Why is c necessary?
Why is c necessary?
target of
close()must be obvious
⇝ resource should not be reassignedeasiest if resource is final
easiest if resource must be assigned
and can be made implicitly final
try (Connection c = connection)Effectively Final Resource
But since Java 8 we have effectively final!
This works in Java 9:
void doSomethingWith(Connection connection)
throws Exception {
try (connection) {
connection.doSomething();
}
}compiler knows that
connectionis not reassigneddevelopers know what effectively final means
Diamond Operator
A little more type inference.
Diamond Operator
Maybe the best example:
List<String> strings = new ArrayList<>();used at a constructor call
tells Java to infer the parametric type
Anonymous Classes
Diamond did not work with anonymous classes:
<T> Box<T> createBox(T content) {
// we have to put the `T` here :(
return new Box<T>(content) { };
}Reason are non-denotable types:
might be inferred by compiler
for anonymous classescan not be expressed by JVM
Infer Denotable Types
Java 9 infers denotable types:
<T> Box<T> createBox(T content) {
return new Box<>(content) { };
}Gives compile error if type is non-denotable:
Box<?> createCrazyBox(Object content) {
List<?> innerList = Arrays.asList(content);
// compile error
return new Box<>(innerList) { };
}SafeVarargs
One less warning you couldn’t do anything about.
Heap Pollution
Innocent looking code…
private <T> Optional<T> firstNonNull(T... args) {
return stream(args)
.filter(Objects::nonNull)
.findFirst();
}Compiler warns (on call site, too):
Possible heap pollution from
parameterized vararg typeHeap Pollution?
For generic varargs argument T… args,
you must not depend on it being a T[]!
private <T> T[] replaceTwoNulls(
T value, T first, T second) {
return replaceAllNulls(value, first, second);
}
private <T> T[] replaceAllNulls(T value, T... args) {
// loop over `args`, replacing `null` with `value`
return args;
}Compiler Warning
Compiler is aware of the problem and warns you.
If you think, everything’s under control:
@SafeVarargs
private <T> Optional<T> firstNonNull(T... args) {
return // [...]
}Or not… In Java 8 this is a compile error!
Invalid SafeVarargs annotation. Instance
method <T>firstNonNull(T...) is not final.But Why?
The @SafeVarargs annotation:
tells the caller that all is fine
only makes sense on methods
that can not be overriden
Which methods can’t be overriden?
⇝ final methods
What about private methods?
⇝ Damn! 😭
@SafeVarargs on Private Methods
Looong story, here’s the point:
In Java 9 @SafeVarargs
can be applied to private methods.
Deprecation Warnings
Another warning you couldn’t do anything about.
Deprecation Warnings
Should this code emit a warning?
// LineNumberInputStream is deprecated
import java.io.LineNumberInputStream;
public class DeprecatedImports {
LineNumberInputStream stream;
}// LineNumberInputStream is deprecated
import java.io.LineNumberInputStream;
@Deprecated
public class DeprecatedImports {
LineNumberInputStream stream;
}Not On Imports
Java 9 no longer emits warnings
for importing deprecated members.
Warning free:
import java.io.LineNumberInputStream;
@Deprecated
public class DeprecatedImports {
LineNumberInputStream stream;
}Collection Factories
Easy creation of ad-hoc collections.
Hope is Pain
Wouldn’t this be awesome?
List<String> list = [ "a", "b", "c" ];
Map<String, Integer> map = [ "one" = 1, "two" = 2 ];Not gonna happen!
language change is costly
binds language to collection framework
strongly favors specific collections
Next Best Thing
List<String> list = List.of("a", "b", "c");
Map<String, Integer> mapImmediate = Map.of(
"one", 1,
"two", 2,
"three", 3);
Map<String, Integer> mapEntries = Map.ofEntries(
Map.entry("one", 1),
Map.entry("two", 2),
Map.entry("three", 3));Interesting Details
collections are immutable
(no immutability in type system, though)collections are value-based
nullelements/keys/values are forbiddeniteration order is random between JVM starts
(except for lists, of course!)
Reactive Streams
The JDK as common ground
for reactive stream libraries.
Reactive Types
Publisherproduces items to consume
can be subscribed to
Subscribersubscribes to publisher
onNext,onError,onComplete
Subscriptionconnection between publisher and subscriber
request,cancel
Reactive Flow
Subscribing
create
Publisher pubandSubscriber subcall
pub.subscribe(sub)pub creates
Subscription script
and callssub.onSubscription(script)subcan storescript
Reactive Flow
Streaming
subcallsscript.request(10)pubcallssub.onNext(element)(max 10x)
Canceling
pubmay callsub.OnError(err)
orsub.onComplete()submay callscript.cancel()
Reactive APIs?
JDK only provides three interfaces
and one simple implementation.
(Also called Flow API.)
No JDK API uses them.
(No reactive HTTP connections etc.)
Stack-Walking
Examining the stack faster and easier.
StackWalker::forEach
void forEach (Consumer<StackFrame>);public static void main(String[] args) { one(); }
static void one() { two(); }
static void two() {
StackWalker.getInstance()
.forEach(System.out::println);
}
// output
StackWalkingExample.two(StackWalking.java:14)
StackWalkingExample.one(StackWalking.java:11)
StackWalkingExample.main(StackWalking.java:10)StackWalker::walk
T walk (Function<Stream<StackFrame>, T>);static void three() {
String line = StackWalker.getInstance().walk(
frames -> frames
.filter(f -> f.getMethodName().contains("one"))
.findFirst()
.map(f -> "Line " + f.getLineNumber())
.orElse("Unknown line");
);
System.out.println(line);
}
// output
Line 11Options
getInstance takes options as arguments:
SHOW_REFLECT_FRAMESfor reflection framesSHOW_HIDDEN_FRAMESe.g. for lambda framesRETAIN_CLASS_REFERENCEforClass<?>
Frames and Traces
forEach and walk operate on StackFrame:
class and method name
class as
Class<?>bytecode index and isNative
Can upgrade to StackTraceElement (expensive):
file name and line number
Performance I
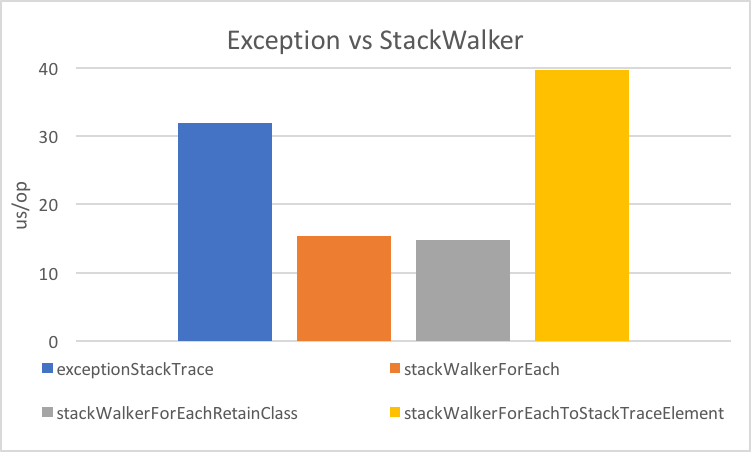
Performance II
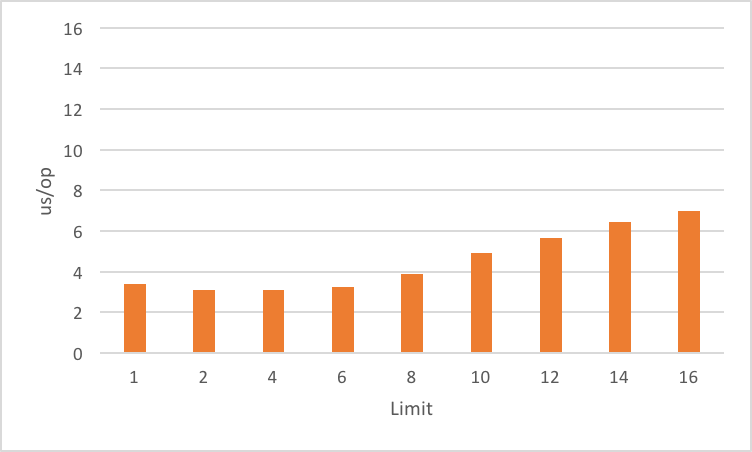
Performance III
creating
StackTraceElementis expensive
(for file name and line number)lazy evaluation pays off for partial traversal
(Benchmarks performed by Arnaud Roger)
Even More New APIs
Stream
Of Nullable
Create a stream of zero or one elements:
long zero = Stream.ofNullable(null).count();
long one = Stream.ofNullable("42").count();Iterate
To use for even less…
iterate(
T seed,
Predicate<T> hasNext,
UnaryOperator<T> next);Example:
Stream
.iterate(1, i -> i<=10, i -> 2*i)
.forEach(System.out::println);
// output: 1 2 4 8Iterate
Counter Example:
Enumeration<Integer> en = // ...
Stream.iterate(
en.nextElement(),
el -> en.hasMoreElements(),
el -> en.nextElement())
.forEach(System.out::println);first
nextElement()then
hasMoreElements()⇝ fail
Take While
Stream as long as a condition is true:
Stream<T> takeWhile(Predicate<T> predicate);Example:
Stream.of("a-", "b-", "c-", "", "e-")
.takeWhile(s -> !s.isEmpty());
.forEach(System.out::print);
// output: a-b-c-Drop While
Ignore as long as a condition is true:
Stream<T> dropWhile(Predicate<T> predicate);Example:
Stream.of("a-", "b-", "c-", "de-", "f-")
.dropWhile(s -> s.length() <= 2);
.forEach(System.out::print);
// output: de-f-Optional
Or
Choose a non-empty Optional:
Optional<T> or(Supplier<Optional<T>> supplier);Find in Many Places
public interface Search {
Optional<Customer> inMemory(String id);
Optional<Customer> onDisk(String id);
Optional<Customer> remotely(String id);
default Optional<Customer> anywhere(String id) {
return inMemory(id)
.or(() -> onDisk(id))
.or(() -> remotely(id));
}
}If Present Or Else
Like ifPresent but do something if empty:
void ifPresentOrElse(
Consumer<T> action,
Runnable emptyAction);Example:
void logLogin(String id) {
findCustomer(id)
.ifPresentOrElse(
this::logCustomerLogin,
() -> logUnknownLogin(id));
}Stream
Turns an Optional into a Stream
of zero or one elements:
Stream<T> stream();Filter-Map …
private Optional<Customer> findCustomer(String id) {
// ...
}
Stream<Customer> findCustomers(List<String> ids) {
return ids.stream()
.map(this::findCustomer)
// now we have a Stream<Optional<Customer>>
.filter(Optional::isPresent)
.map(Optional::get)
}… in one Step
private Optional<Customer> findCustomer(String id) {
// ...
}
Stream<Customer> findCustomers(List<String> ids) {
return ids.stream()
.map(this::findCustomer)
// now we have a Stream<Optional<Customer>>
// we can now filter-map in one step
.flatMap(Optional::stream)
}From Eager to Lazy
List<Order> getOrders(Customer c) is expensive:
List<Order> findOrdersForCustomer(String id) {
return findCustomer(id)
.map(this::getOrders) // eager
.orElse(new ArrayList<>());
}
Stream<Order> findOrdersForCustomer(String id) {
return findCustomer(id)
.stream()
.map(this::getOrders) // lazy
.flatMap(List::stream);
}OS Processes
Simple Example
ls /home/nipa/tmp | grep pdfPath dir = Paths.get("/home/nipa/tmp");
ProcessBuilder ls = new ProcessBuilder()
.command("ls")
.directory(dir.toFile());
ProcessBuilder grepPdf = new ProcessBuilder()
.command("grep", "pdf")
.redirectOutput(Redirect.INHERIT);
List<Process> lsThenGrep = ProcessBuilder
.startPipeline(List.of(ls, grepPdf));Extended Process
Cool new methods on Process:
boolean supportsNormalTermination();long pid();CompletableFuture<Process> onExit();Stream<ProcessHandle> children();Stream<ProcessHandle> descendants();ProcessHandle toHandle();
New ProcessHandle
New functionality actually comes from ProcessHandle.
Interesting static methods:
Stream<ProcessHandle> allProcesses();Optional<ProcessHandle> of(long pid);ProcessHandle current();
More Information
ProcessHandle can return Info:
command, arguments
start time
CPU time
Even More Updated APIs
Unified Logging </td></tr>
Observing the JVM at work.
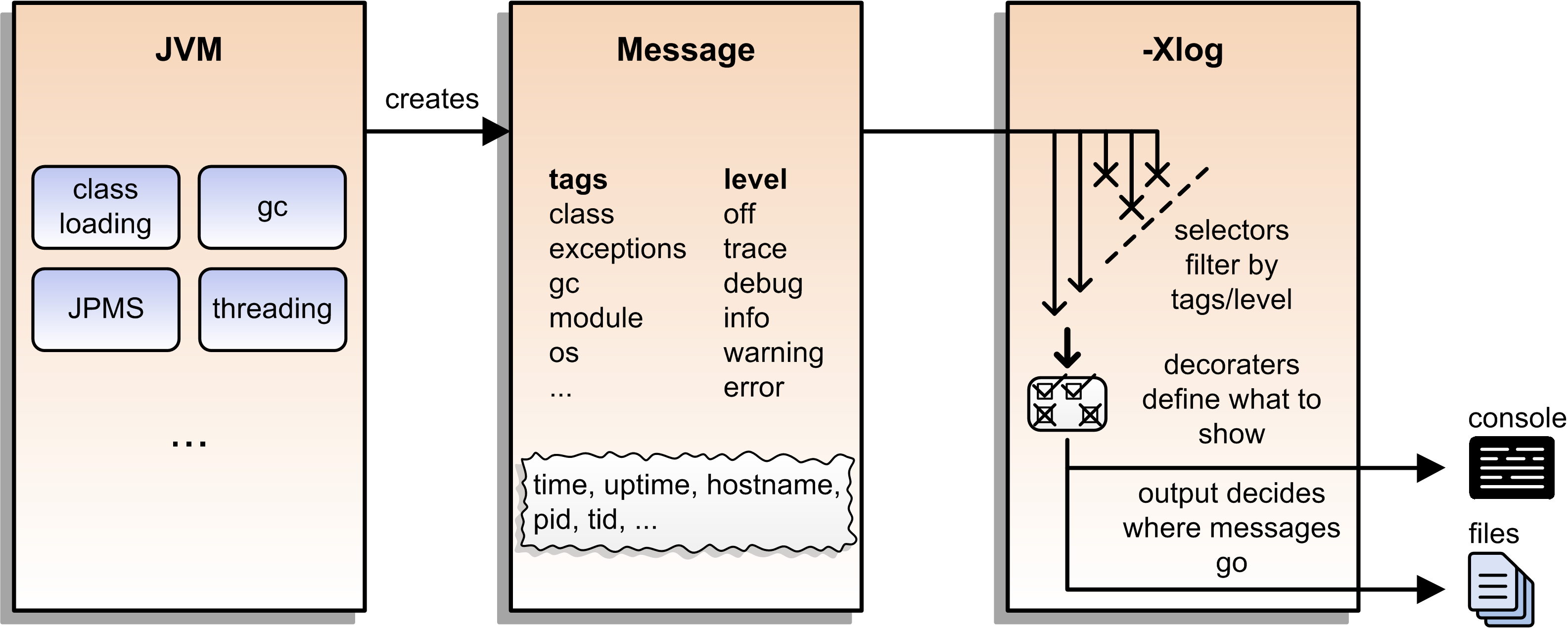
Unified Logging
New logging infrastructure for the JVM
(e.g. OS interaction, threading, GC, etc.):
JVM log messages pass through new mechanism
works similar to known logging frameworks:
textual messages
log level
time stamps
meta information (like subsystem)
output can be configured with
-Xlog
Unified Logging
First Try
Plain use of -Xlog:
$ java -Xlog -version
# truncated a few messages
> [0.002s][info][os ] HotSpot is running ...
# truncated a lot of messagesYou can see:
JVM uptime (2ms)
log level (
info)tags (
os)message
Configuring -Xlog
This can be configured:
which messages to show
where messages go
what messages should say
How? -Xlog:help lists all options.
Which Messages?
Configure with selectors: $TAG_SET=$LEVEL:
# "exactly gc" on "warning"
-Xlog:gc=warning
# "including gc" on "warning"
-Xlog:gc*=warning
# "exactly gc and os" on "debug"
-Xlog:gc+os=debug
# "gc" on "debug" and "os" on warning
-Xlog:gc=debug,os=warningDefaults:
-Xlog # the same as -Xlog:all
-Xlog:$TAG # same as -Xlog:$TAG=infoWhere Do Messages Go?
Three possible locations:
stdout(default)stderrfile=$FILENAME
(file rotation is possible)
Example:
# all debug messages into application.log
-Xlog:all=debug:file=application.logWhich Information?
Decorators define what is shown:
time: time and date (also in ms and ns)uptime: time since JVM start (also in ms and ns)pid: process identifiertid: thread identifierlevel: log leveltags: tag-set
Example:
# show uptime in ms and level
-Xlog:all:stdout:level,uptimemillisPut Together
Formal syntax:
-Xlog:$SELECTORS:$OUTPUT:$DECORATORS:$OUTPUT_OPTS$SELECTORSare pairs of tag sets and log levels
(the docs call this what-expression)$OUTPUTisstdout,stderr, orfile=<filename>$DECORATORSdefine what is shown$OUTPUT_OPTSconfigure file rotation
Elements have to be defined from left to right.
(No skipping!)
Multi-Release JARs
"Do this on Java X, do that on Java Y."
Version Dependence
Main calls Version:
public class Main {
public static void main(String[] args) {
System.out.println(new Version().get());
}
}Version Dependence
Version exists twice:
public class Version {
public String get() { return "Java 8"; }
}
public class Version {
public String get() { return "Java 9+"; }
}(Btw, IDEs hate this!)
Creating A Multi‑Release JAR
Now, here’s the magic:
compile
MainandVersion[8]toout/java-8compile
Version[9]toout/java-9use new
jarflag--release:jar --create --file out/mr.jar -C out/java-8 . --release 9 -C out/java-9 .
JAR Content
└ dev
└ nipafx ... (moar folders)
├ Main.class
└ Version.class
└ META-INF
└ versions
└ 9
└ dev
└ nipafx ... (moar folders)
└ Version.classRun!
With java -cp out/mr.jar …Main:
prints
"Java 8"on Java 8prints
"Java 9+"on Java 9 and later
Great Success!
Redirected Platform Logging
Use your logging framework of choice
as backend for JDK logging.
Loggers and Finders
New logging infrastructure for the core libraries
(i.e. this does not apply to JVM log messages!)
new interface
System.Loggerused by JDK classes
instances created by
System.LoggerFinder
The interesting bit:
LoggerFinder is a service!
Creating a Logger
public class SystemOutLogger implements Logger {
public String getName() { return "SystemOut"; }
public boolean isLoggable(Level level) { return true; }
public void log(
Level level, ResourceBundle bundle,
String format, Object... params) {
System.out.println(/* ...*/);
}
// another, similar `log` method
}Creating a LoggerFinder
public class SystemOutLoggerFinder
extends LoggerFinder {
public Logger getLogger(
String name, Module module) {
return new SystemOutLogger();
}
}Registering the Service
Module descriptor for system.out.logger:
module system.out.logger {
provides java.lang.System.LoggerFinder
with system.out.logger.SystemOutLoggerFinder;
}Module system and JDK take care of the rest!
Even More New JVM Features
Compact Strings
Going from UTF-16 to ISO-8859-1.
Strings and memory
20% - 30% of heap are
char[]forStringa
charis UTF-16 code unit ⇝ 2 bytesmost strings only require ISO-8859-1 ⇝ 1 byte
10% - 15% of memory is wasted!
Compact Strings
For Java 9, String was changed:
uses
byte[]instead ofchar[]bytes per character:
1 if all characters are ISO-8859-1
2 otherwise
Only possible because String makes
defensive copies of all arguments.
Performance
Simple benchmark:
(by Aleksey Shipilëv)
String method = generateString(size);
public String work() {
return "Calling method \"" + method + "\"";
}Depending on circumstances:
throughput 1.4x
garbage less 1.85x
More
Background on String
performance improvements:
Indified String Concatenation
"Improving" + "String" + "Concatenation"
String Concatenation
What happens when you run:
String s = greeting + ", " + place + "!";bytecode uses
StringBuilderJIT may (!) recognize and optimize
by writing content directly to newbyte[]breaks down quickly
(e.g. withlongordouble)
Why Not Create Better Bytecode?
new optimizations create new bytecode
new optimizations require recompile
test matrix JVMs vs bytecodes explodes
Why Not Call String::concat?
There is no such method.
concat(String… args)requirestoStringconcat(Object… args)requires boxing
Nothing fancy can be done
because compiler must use public API.
Invokedynamic
Invokedynamic came in Java 7:
compiler creates a recipe
runtime has to process it
defers decisions from compiler to runtime
(Used for lambda expressions and in Nashorn.)
Indy To The Rescue
With Indy compiler can express
"concat these things"
(without boxing!)
JVM executes by writing content
directly to new byte[].
Performance
Performance Of Indified Compact String Concat
More
Background on String
performance improvements:
Even More Performance
Java 10
Sources: github.com/nipafx/demo-java-x
Local-Variable Type Inference
Less typing, but still strongly typed.
Type Duplication
We’re used to duplicating
type information:
URL nipafx = new URL("http://nipafx.dev");
URLConnection connection = nipafx.openConnection();
Reader reader = new BufferedReader(
new InputStreamReader(
connection.getInputStream()));Not so bad?
Type Duplication
What about this?
No no = new No();
AmountIncrease<BigDecimal> more =
new BigDecimalAmountIncrease();
HorizontalConnection<LinePosition, LinePosition>
jumping =
new HorizontalLinePositionConnection();
Variable variable = new Constant(5);
List<String> names = List.of("Max", "Maria");Type Deduplication
Can’t somebody else do that?
Compiler knows the types!
Enter var:
var nipafx = new URL("http://nipafx.dev");
var connection = nipafx.openConnection();
var reader = new BufferedReader(
new InputStreamReader(
connection.getInputStream()));Locality
How much information is used for inference?
type inference can be
arbitrarily complex/powerfulcritical resource is not
compiler but developercode should be readable
(without compiler/IDE)
⇝ Better to keep it simple!
"Action at a distance"
// inferred as `int`
var id = 123;
if (id < 100) {
// very long branch
} else {
// oh boy, much more code...
}
// now we add this line:
id = "124";What type should id be?
Where does the error show up?
Rules of var
Hence, var only works in limited scopes:
compiler infers type from right-hand side
⇝ rhs has to exist and define a typeonly works for local variables,
for,try
⇝ novaron fields or in method signaturesalso on lambda parameters ⑪
⇝ annotate inferred type on lambda parameters
Rules of var
Two more:
not a keyword, but a reserved type name
⇝ variables/fields can be namedvarcompiler writes type into bytecode
⇝ no run-time component
What About Readability?
This is about readability!
less redundancy
more intermediate variables
more focus on variable names
aligned variable names
Aligned Variable Names
var no = new No();
var more = new BigDecimalAmountIncrease();
var jumping = new HorizontalLinePositionConnection();
var variable = new Constant(5);
var names = List.of("Max", "Maria");What About Readability?
Still think omitting types is always bad?
Ever wrote a lambda without declaring types?
rhetoricalQuestion.answer(yes -> "see my point?");Style Guidelines
Principles from the official style guidelines:
Reading code is more important than writing it.
Code should be clear from local reasoning.
Code readability shouldn’t depend on IDEs.
Explicit types are a tradeoff.
Style Guidelines
Guidelines:
Choose variable names that provide useful info.
Minimize the scope of local variables.
Consider
varwhen the initializer provides sufficient information to the reader.Use
varto break up chained or nested expressions.Don’t worry too much about "programming to the interface".
Take care when using
varwith diamonds or generics.Take care when using
varwith literals.
Style Guidelines
Choose variable names that provide useful info.
/* ✘ */ var u = UserRepository.findUser(id);
/* ✔ */ var user = UserRepository.findUser(id);
/* 👍*/ var userToLogIn = UserRepository.findUser(id);Style Guidelines
Minimize the scope of local variables.
// ✘
var id = 123;
if (id < 100) {
// very long branch
} else {
// oh boy, much more code...
}
LOGGER.info("... " + id);
// ✔ replace branches with method callsStyle Guidelines
Consider
varwhen the initializer provides
sufficient information to the reader.
/* ✘ */ var user = Repository.find(id);
/* ✔ */ var user = UserRepository.findUser(id);
/* 👍*/ var user = new User(id);Style Guidelines
Use
varto break up chained or nested expressions.
// ✘
return Canvas
.activeCanvas()
.drawings()
.filter(Drawing::isLine)
.map(drawing -> (HorizontalConnection) drawing)
// now we have lines
.filter(line -> length(line) == 7)
.map(this::generateSquare)
// now we have squares
.map(this::createRandomColoredSquare)
.map(this::createRandomBorderedSquare)
.collect(toList());Style Guidelines
Use
varto break up chained or nested expressions.
// ✔
var lines = Canvas
.activeCanvas()
.drawings()
.filter(Drawing::isLine)
.map(drawing -> (HorizontalConnection) drawing)
var squares = lines
.filter(line -> length(line) == 7)
.map(this::generateSquare);
return squares
.map(this::createRandomColoredSquare)
.map(this::createRandomBorderedSquare)
.collect(toList());Style Guidelines
Don’t worry too much about
"programming to the interface".
// inferred as `ArrayList` (not `List`),
// but that's ok
var users = new ArrayList<User>();Careful when refactoring:
extracting methods that use
var-ed variables
puts concrete types into method signatureslook out and replace with most general type
Style Guidelines
Take care when using
varwith diamonds or generics.
// ✘ infers `ArrayList<Object>`
var users = new ArrayList<>();
// ✔ infers `ArrayList<User>`
var users = new ArrayList<User>();Style Guidelines
Take care when using
varwith literals.
// ✘ when used with `var`, these
// variables become `int`
byte b = 42;
short s = 42;
long l = 42More on var
First Contact With
varIn Java 10
💻 tiny.cc/java-var / ▶ tiny.cc/java-var-ytcheat sheet (⇜ print when getting started!)
varand …
Stream
Collect Unmodifiable
Create unmodifiable collections
(in the sense of List::of et al)
with Collectors:
Collector<T, ?, List<T>> toUnmodifiableList();
Collector<T, ?, Set<T>> toUnmodifiableSet();
Collector<T, ?, Map<K,U>> toUnmodifiableMap(
Function<T, K> keyMapper,
Function<T, U> valueMapper);
// plus overload with merge functionOptional
Or Else Throw
Optional::get invites misuse
by calling it reflexively.
Maybe get wasn’t the best name?
New:
T orElseThrow()Works exactly as get,
but more self-documenting.
Aligned Names
Name in line with other accessors:
T orElse(T other)
T orElseGet(Supplier<T> supplier)
T orElseThrow()
throws NoSuchElementException
T orElseThrow(
Supplier<EX> exceptionSupplier)
throws XGet Considered Harmful
Collection Factories
Creating immutable copies:
/* on List */ List<E> copyOf(Collection<E> coll);
/* on Set */ Set<E> copyOf(Collection<E> coll);
/* on Map */ Map<K, V> copyOf(Map<K,V> map);Great for defensive copies:
public Customer(List<Order> orders) {
this.orders = List.copyOf(orders);
}Even More New Methods
Reader.transferTo(Writer);
DateTimeFormatter.localizedBy(Locale locale);Even More New JVM Features
alternative memory device support (JEP 316)
Application Class-Data Sharing
Improving application launch times.
Class-Data
JVM steps to execute a class’s bytecode:
looks up class in JAR
loads bytecode
verifies bytecode
stores class-data in
internal data structure
This takes quite some time.
If classes don’t change, the resulting
class-data is always the same!
Class-Data Sharing
Idea behind class-data sharing:
create class-data once
dump it into an archive
reuse the archive in future launches
(file is mapped into memory)
Effects
My experiments with a large desktop app
(focusing on classes required for launch):
archive has 250 MB for ~24k classes
launch time reduced from 15s to 12s
Bonus: Archive can be shared across JVMs.
Class-Data Sharing
Two variants:
- CDS
just for JDK classes
- AppCDS
JDK + application classes
CDS - Step #1
Create JDK archive:
# possibly as root
java -Xshare:dumpJava 12+ downloads include
CDS archive for JDK classes.
CDS - Step #2
Use the archive:
$ java
-Xshare:on
# [... class path for app and deps ...]
org.example.MainIf archive is missing or faulty:
-Xshare:onfails fast-Xshare:auto(default) ignores archive
(Slides rely on default, i.e. no -Xshare.)
AppCDS
Create an AppCDS archive:
manually ⑩+
dynamically on ⑬+
Now manually, later dynamically.
AppCDS - Step #0
To manually create an AppCDS archive,
first create a list of classes
$ java
-XX:DumpLoadedClassList=classes.lst
# [... class path for app and deps ...]
org.example.MainThen, classes.lst contains
slash-separated names of loaded classes.
AppCDS - Step #1
Use the list to create the archive:
$ java
-Xshare:dump
-XX:SharedClassListFile=classes.lst
-XX:SharedArchiveFile=app-cds.jsa
# [... class path for app and deps ...]Creates archive app-cds.jsa.
AppCDS - Step #2
Use the archive:
$ java
-XX:SharedArchiveFile=app-cds.jsa
# [... class path for app and deps ...]
org.example.MainHeed The Class Path
What are the two biggest challenges
in software development?
naming
cache invalidation
off-by-one errors
Heed The Class Path
The archive is a cache!
It’s invalid when:
a JAR is updated
class path is reordered
a JAR is added
(unless when appended)
Heed The Class Path
To invalidate the archive:
during creation:
Java stores used class path in archive
class path may not contain wild cards
class path may not contain exploded JARs
when used:
Java checks whether stored path
is prefix of current path
Module Path?
Class path, class path…
what about the module path?
In this release, CDS cannot archive classes from user-defined modules (such as those specified in
--module-path). We plan to add that support in a future release.
— JEP 310
More On (App)CDS
For more, read this article:
tiny.cc/app-cds
Observe sharing with
-Xlog:class+load
(unified logging)
Even More Performance
Java 11
Sources: github.com/nipafx/demo-java-x
Migration
I recently did a stream on that:
twitch.tv/videos/614048355
TL;DR:
Replace Java EE modules
with regular dependencies
String
Strip White Space
Getting rid of white space:
String strip();
String stripLeading();
String stripTrailing();Only at beginning and end of string:
" foo bar ".strip().equals("foo bar");What About Trim?
Wait, what about trim()?
trim()defines white space as:any character whose codepoint
is less than or equal to'U+0020'
(the space character)strip()relies onCharacter::isWhitespace,
which covers many more cases
Is Blank?
Is a string only white space?
boolean isBlank();Functionally equivalent to:
string.isBlank() == string.strip().isEmpty();Life Hack
As soon as Java APIs get new method,
scour StackOverflow for easy karma!

Life Hack
Formerly accepted answer:
😍
Life Hack
Ta-da!
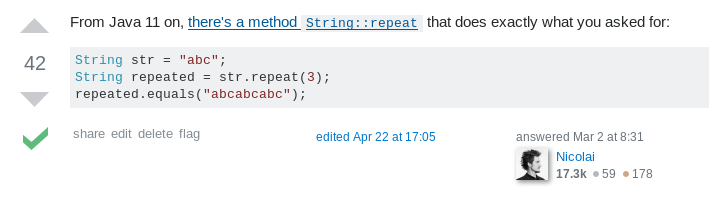
Streaming Lines
Processing a string’s lines:
Stream<String> lines();splits a string on
"\n","\r","\r\n"lines do not include terminator
more performant than
split("\R")lazy!
Even More New Methods
Optional.isEmpty();
Path.of(String); // ~ Paths.get(String)
Files.readString(Path);
Files.writeString(Path, CharSequence, ...);
Reader.nullReader();
Writer.nullWriter();
InputStream.nullInputStream();
OutputStream.nullOutputStream();
DateTimeFormatter.localizedBy(Locale locale);Launch Source File
Faster feedback with fewer tools.
Launching A Single Source File
Compiling and running
simple Java programs is verbose.
Not any more!
java HelloJava11.javaBackground
How it works:
compiles source into memory
runs from there
Details:
requires module jdk.compiler
processes options like class/module path et al.
interprets
@filesfor easier option management
Use Cases
Mostly similar to jshell:
easier demonstrations
more portable examples
experimentation with new language features
(combine with--enable-preview)
But also: script files!
Scripts
Steps towards easier scripting:
arbitrary file names
shebang support
Arbitrary File Names
Use --source if file doesn’t end in .java:
java --source 11 hello-java-11Shebang Support
To create "proper scripts":
include shebang in source:
#!/opt/jdk-11/bin/java --source 11name script and make it executable
execute it as any other script:
# from current directory: ./hello-java-11 # from PATH: hello-java-11
Even More New JVM Features
Even More Performance
Fun with var
Sources: github.com/nipafx/demo-java-x
Intersection Types
Motivation
Sometimes you need a type
that implements two interfaces
without creating a new interface.
For example:
You need something
that is Closeable and an Iterator
without creating CloseableIterator.
Intersection types
Given two types, the intersection type
is the set of variables that are of both types.
An intersection type has the API of both types!
For example:
A variable of type Closeable & Iterator<E>
is both Closeable and an Iterator<E>.
It has close() and hashNext()/next()
Code
Intersection types
in method signatures, express with generics:
public <T extends Closeable & Iterator<String>> T createCloseableIterator(...) { ... } public <E, T extends Closeable & Iterator<E>> E firstMatch(T elements, ...) { ... }for variables use
var:var elements = createCloseableIterator(true); firstMatch(elements, ...);
Evaluation
Downsides:
combination of non-trivial Java features:
generics with bounded wildcards
type inference
refactoring becomes harder
But:
intersection types are known concept
can be really helpful in a bind
Add to tool box; use with care.
More on intersection types
I’ve written a blog post:
nipafx.dev/java-var-intersection-types
Traits
Motivation
Sometimes you need to attach
prepared functionality to an instance
without creating a new type.
For example:
You have a Megacorp instance and an
IsSuccessful-interface that you
want to attach to it.
Traits
A trait extends an interface
and implements additional behavior.
The language needs to offer a simple way
to "attach" that trait to an instance at hand.
Code
Traits
create a functional, delegating interface:
@FunctionalInterface interface MegacorpDelegate extends Megacorp { Megacorp delegate(); // implement `Megacorp` with default methods // by forwarding calls to `delegate()` }create traits as interfaces:
interface IsEvil extends Megacorp { default boolean isEvil() { return true; } }
Traits
cast lambda to desired intersection
and assign tovar-ed variable:var corp = (MegacorpDelegate & IsEvil) () -> original;
Evaluation
Downsides:
combination of non-trivial Java features:
lambda as poly expression
type inference
default methods
refactoring becomes harder
(see intersection types)delegating interface is cumbersome
breaks in collections (!)
Never use in "real" code!
More on traits
I’ve written a blog post:
nipafx.dev/java-var-traits
Ad-hoc Fields And Methods
Motivation
Sometimes you need to extend a type
with a field or a method.
But not enough to create a new subtype.
Maybe with an anonymous class?
Anonymous class
new SimpleMegacorp(...) {
final BigDecimal SUCCESS_BOUNDARY =
new BigDecimal("1000000000000");
boolean isSuccessful() {
return earnings()
.compareTo(SUCCESS_BOUNDARY) > 0;
}
};Code
Ad-hoc fields & methods
create anonymous class with
additional fields and/or methodsassigned to
var-ed variable
var corp = new SimpleMegacorp(...) {
final BigDecimal SUCCESS_BOUNDARY =
new BigDecimal("1000000000000");
boolean isSuccessful() {
return earnings()
.compareTo(SUCCESS_BOUNDARY) > 0;
}
};
corp.isSuccessful();Evaluation
Downsides:
anonymous class is verbose (e.g. in stream)
combination of non-trivial Java features:
anonymous classes
type inference
impedes refactoring (!)
Prefer the alternatives!
Alternatives
More on ad-hoc fields and methods
I’ve written a blog post:
nipafx.dev/java-var-anonymous-classes-tricks
Java 12
Sources: github.com/nipafx/demo-java-x
Switch Expressions
More powerful switch.
Switching
Say you’re facing the dreaded ternary Boolean …
public enum TernaryBoolean {
TRUE,
FALSE,
FILE_NOT_FOUND
}... and want to convert it to a regular Boolean.
Switch Statement
Before Java 12, you might have done this:
boolean result;
switch (ternaryBool) {
case TRUE:
result = true; break;
case FALSE:
result = false; break;
case FILE_NOT_FOUND:
var ex = new UncheckedIOException(
"This is ridiculous!",
new FileNotFoundException());
throw ex;
default:
var ex2 = new IllegalArgumentException(
"Seriously?! 😠");
throw ex2;
}Switch Statement
Lots of room for improvements:
default fall-through is annoying
resulthandling is roundaboutlacking compiler support is error-prone
Switch Statement
This is better:
public boolean convert(TernaryBoolean ternaryBool) {
switch (ternaryBool) {
case TRUE:
return true;
case FALSE:
return false;
case FILE_NOT_FOUND:
throw new UncheckedIOException(
"This is ridiculous!",
new FileNotFoundException());
default:
throw new IllegalArgumentException(
"Seriously?! 😠");
}
}Switch Statement
Better:
returnprevents fall-throughresults are created on the spot
compiler complains on missing branches
But:
defaultis not really necessarycreating a method is not always
possible or convenient
Switch Expression
Enter switch expressions:
boolean result = switch(ternaryBool) {
case TRUE -> true;
case FALSE -> false;
case FILE_NOT_FOUND ->
throw new UncheckedIOException(
"This is ridiculous!",
new FileNotFoundException());
};Two things to note:
switch"has a result"
⇝ it’s an expression, not a statementlambda-style arrow syntax
Preview Feature
Note:
In Java 12 & 13, switch expressions are
a preview language feature!
must be enabled with
--enable-preview
(onjavacandjava).in IntelliJ, set the module’s language level to
12 (Preview) - … or 13 (Preview) - …in Eclipse, go to Compiler Settings
and check Enable preview features
Expression vs Statement
Statement:
if (condition)
result = doThis();
else
result = doThat();Expression:
result = condition
? doThis()
: doThat();Expression vs Statement
Statement:
imperative construct
guides computation, but has no result
Expression:
is computed to a result
Expression vs Statement
For switch:
if used with an assignment,
switchbecomes an expressionif used "stand-alone", it’s
treated as a statement
This results in different behavior
(more on that later).
Arrow vs Colon
You can use : and -> with
expressions and statements, e.g.:
boolean result = switch(ternaryBool) {
case TRUE: yield true;
case FALSE: yield false;
case FILE_NOT_FOUND:
throw new UncheckedIOException(
"This is ridiculous!",
new FileNotFoundException());
};switchis used as an expressionyield resultreturnsresult⑬ introduced
yield- in it wasbreak
Arrow vs Colon
Whether you use arrow or colon
results in different behavior
(more on that later).
Switch Evolution
general improvements
multiple case labels
specifics of arrow form
no fall-through
statement blocks
specifics of expressions
poly expression
returning early
exhaustiveness
Multiple Case Labels
Statements and expressions,
in colon and arrow form
can use multiple case labels:
String result = switch (ternaryBool) {
case TRUE, FALSE -> "sane";
// `default, case FILE_NOT_FOUND -> ...`
// does not work (neither does other way
// around), but that makes sense because
// using only `default` suffices
default -> "insane";
};No Fall-Through
Whether used as statement or expression,
the arrow form has no fall-through:
switch (ternaryBool) {
case TRUE, FALSE ->
System.out.println("Bool was sane");
// in colon-form, if `ternaryBool` is `TRUE`
// or `FALSE`, we would see both messages;
// in arrow-form, only one branch is executed
default ->
System.out.println("Bool was insane");
}Statement Blocks
Whether used as statement or expression,
the arrow form can use statement blocks:
boolean result = switch (Bool.random()) {
case TRUE -> {
System.out.println("Bool true");
yield true;
}
case FALSE -> {
System.out.println("Bool false");
yield false;
}
// cases `FILE_NOT_FOUND` and `default`
};Statement Blocks
Natural way to create scope:
boolean result = switch (Bool.random()) {
// cases `TRUE` and `FALSE`
case FILE_NOT_FOUND -> {
var ex = new UncheckedIOException(
"This is ridiculous!",
new FileNotFoundException());
throw ex;
}
default -> {
var ex = new IllegalArgumentException(
"Seriously?! 🤬");
throw ex;
}
};Poly Expression
A poly expression
has no definitive type
can be one of several types
Lambdas are poly expressions:
Function<String, String> fun = s -> s + " ";
UnaryOperator<String> op = s -> s + " ";Poly Expression
Whether in colon or arrow form,
a switch expression is a poly expression.
How it’s type is determined,
depends on the target type:
// target type known: String
String result = switch (ternaryBool) { ... }
// target type unknown
var result = switch (ternaryBool) { ... }Poly Expression
If target type is known, all branches must conform to it:
String result = switch (ternaryBool) {
case TRUE, FALSE -> "sane";
default -> "insane";
};If target type is unknown, the compiler infers a type:
// compiler infers super type of `String` and
// `IllegalArgumentException` ~> `Serializable`
var serializableMessage = switch (bool) {
case TRUE, FALSE -> "sane";
default -> new IllegalArgumentException("insane");
};Returning Early
Whether in colon or arrow form,
you can’t return early from a switch expression:
public String sanity(Bool ternaryBool) {
String result = switch (ternaryBool) {
// compile error:
// "return outside
// of enclosing switch expression"
case TRUE, FALSE -> { return "sane"; }
default -> { return "This is ridiculous!"; }
};
}Exhaustiveness
Whether in colon or arrow form,
a switch expression checks exhaustiveness:
// compile error:
// "the switch expression does not cover
// all possible input values"
boolean result = switch (ternaryBool) {
case TRUE -> true;
// no case for `FALSE`
case FILE_NOT_FOUND ->
throw new UncheckedIOException(
"This is ridiculous!",
new FileNotFoundException());
};Exhaustiveness
No compile error for missing default:
// compiles without `default` branch because
// all cases for `ternaryBool` are covered
boolean result = switch (ternaryBool) {
case TRUE -> true;
case FALSE -> false;
case FILE_NOT_FOUND ->
throw new UncheckedIOException(
"This is ridiculous!",
new FileNotFoundException());
};Compiler adds in default branch.
More on switch
Definitive Guide To Switch Expressions
New APIs
CompactNumberFormat(JDK-8188147)
String
Changing Indentation
Use String::indent to add or remove
leading white space:
String oneTwo = " one\n two\n";
oneTwo.indent(0).equals(" one\n two\n");
oneTwo.indent(1).equals(" one\n two\n");
oneTwo.indent(-1).equals("one\n two\n");
oneTwo.indent(-2).equals("one\ntwo\n");Would have been nice to pass resulting indentation,
not change in indentation.
Changing Indentation
String::indent normalizes line endings
so each line ends in \n:
"1\n2".indent(0).equals("1\n2\n");
"1\r\n2".indent(0).equals("1\n2\n");
"1\r2\n".indent(0).equals("1\n2\n");
"1\n2\n".indent(0).equals("1\n2\n");Transforming Strings
New method on String:
public <R> R transform(Function<String, R> f) {
return f.apply(this);
}Use to chain calls instead of nesting them:
User newUser = parse(clean(input));
User newUser = input
.transform(this::clean)
.transform(this::parse);Makes more sense at end of long call chain
(stream pipeline?) to chain more calls.
Transforming things
Maybe other classes get transform, too!
Great for "chain-friendly" APIs like Stream, Optional:
// in a museum...
tourists.stream()
.map(this::letEnter)
.transform(this::groupsOfFive)
.forEach(this::giveTour)
Stream<TouristGroup> groupsOfFive(
Stream<Tourist> tourists) {
// this is not trivial,
// but at least possible
}⇝ Practice with String::transform!
Stream
Teeing Collector
Collect stream elements in two collectors
and combine their results:
// on Collectors
Collector<T, ?, R> teeing(
Collector<T, ?, R1> downstream1,
Collector<T, ?, R2> downstream2,
BiFunction<R1, R2, R> merger);Teeing Collector
Example:
Statistics stats = Stream
.of(1, 2, 4, 5)
.collect(teeing(
// Collector<Integer, ?, Integer>
summingInt(i -> i),
// Collector<Integer, ?, Double>
averagingInt(i -> i),
// BiFunction<Integer, Double, Statistics>
Statistics::of));
// stats = Statistics {sum=12, average=3.0}Completable Future
Recap on API Basics
// start an asynchronous computation
public static CompletableFuture<T> supplyAsync(
Supplier<T>);
// attach further steps
public CompletableFuture<U> thenApply(Function<T, U>);
public CompletableFuture<U> thenCompose(
Function<T, CompletableFuture<U>);
public CompletableFuture<Void> thenAccept(Consumer<T>);
// wait for the computation to finish and get result
public T join();Recap on API Basics
Example:
public void loadWebPage() {
String url = "http://nipafx.dev";
CompletableFuture<WebPage> future = CompletableFuture
.supplyAsync(() -> webRequest(url))
.thenApply(html -> new WebPage(url, html));
// ... do other stuff
future.join();
}
private String webRequest(String url) {
// make request to URL and return HTML
// (this can take a while)
}Recap on Completion
A pipeline or stage completes when
the underlying computation terminates.
it completes normally if
the computation yields a resultit completes exceptionally if
the computation results in an exception
Recap on Error Recovery
Two methods to recover errors:
// turn the error into a result
CompletableFuture<T> exceptionally(Function<Throwable, T>);
// turn the result or error into a new result
CompletableFuture<U> handle(BiFunction<T, Throwable, U>);They turn exceptional completion of the previous stage
into normal completion of the new stage.
Recap on Error Recovery
Example:
loadUser(id)
.thenCompose(this::loadUserHistory)
.thenCompose(this::createRecommendations)
.exceptionally(ex -> {
log.warn("Recommendation error", ex)
return createDefaultRecommendations();
})
.thenAccept(this::respondWithRecommendations);Composeable Error Recovery
Error recovery accepts functions
that produce CompletableFuture:
exceptionallyCompose(
Function<Throwable, CompletionStage<T>>)Recap on (A)Synchronicity
Which threads actually compute the stages?
supplyAsync(Supplier<T>)is executed
in the common fork/join poolfor other stages it’s undefined:
could be the same thread as the previous stage
could be another thread in the pool
could be the thread calling
thenAcceptet al.
How to force async computation?
Recap on (A)Synchronicity
All "composing" methods
have an …Async companion, e.g.:
thenApplyAsync(Function<T, U>);
thenAcceptAsync(Consumer<T>)They submit each stage as a separate task
to the common fork/join pool.
Async Error Recovery
Error recovery can be asynchronous:
CompletableFuture<T> exceptionallyAsync(
Function<Throwable, T>)
CompletableFuture<T> exceptionallyComposeAsync(
Function<Throwable, CompletableFuture<T>>)There are overloads that accept Executor.
Even More New I/O Methods
Files.mismatch(Path, Path);Even More New JVM Features
constants API (JEP 334)
HmacPBE (JDK-8215450)
finer PKCS12 KeyStore configuration (JDK-8076190)
Application Class Data Sharing
Even More Performance
Java 13
Sources: github.com/nipafx/demo-java-x
Text Blocks
Multiline strings. Finally.
Multiline Strings
Text blocks are straightforward:
String haikuBlock = """
worker bees can leave
even drones can fly away
the queen is their slave""";
System.out.println(haiku);
// > worker bees can leave
// > even drones can fly away
// > the queen is their slaveline breaks are normalized to
\nintentional indentation remains
accidental indentation is removed
Syntax
can be used in same place
as"string literals"start with
"""and new lineend with
"""on the last line of content
on its own line
Position of closing """ decides
whether string ends with "\n".
Vs String Literals
Compare to:
String haikuLiteral = ""
+ "worker bees can leave\n"
+ " even drones can fly away\n"
+ " the queen is their slave";haikuBlock.equals(haikuLiteral)thanks to string interning even
haikuBlock == haikuLiteral
⇝ No way to discern source at run time!
Line Endings
Line ending depends on configuration.
Source file properties influence semantics?
Text block lines always end with \n!
Escape sequences are translated afterwards:
String windows = """
Windows\r
line\r
endings\r
"""Indentation
Compiler discerns:
accidental indentation
(from code style; gets removed)essential indentation
(within the string; remains)
How?
Accidental Indentation
closing
"""are on their own line
⇝ their indentation is accidentalotherwise, line with smallest indentation
⇝ its indentation is accidental
Indentation
Accidental vs intentional indentation
(separated with |):
String haikuBlock = """
|worker bees can leave
| even drones can fly away
| the queen is their slave""";
String haikuBlock = """
| worker bees can leave
| even drones can fly away
| the queen is their slave
""";Manual Indentation
To manually manage indentation:
String::stripIndentString::indent
Escape Sequences
Text blocks are not raw:
escape sequences work (e.g.
\r)escape sequences are necessary
But: " is not special!
String phrase = """
{
greeting: "hello",
audience: "text blocks",
}
""";⇝ Way fewer escapes in HTML/JSON/SQL/etc.
More on Text Blocks
Even More New I/O Methods
FileSystems.newFileSystem(Path, ...);
ByteBuffer.get(int, ...)
ByteBuffer.put(int, ...)Dynamic AppCDS
Java 13 can create archive when
program exits (without crash):
steps #0 and #1 are replaced by:
$ java -XX:ArchiveClassesAtExit=dyn-cds.jsa # [... class path for app and deps ...] org.example.Mainstep #2 as before:
$ java -XX:SharedArchiveFile=app-cds.jsa # [... class path for app and deps ...] org.example.Main
Dynamic AppCDS
The dynamic archive:
builds on the JDK-archive
contains all loaded app/lib classes
including those loaded by
user-defined class loaders
Even More Performance
Shenandoah improvements:
internals (JDK-8221766, JDK-8224584)
more platforms (JDK-8225048, JDK-8223767)
ZGC improvements:
implements
-XX:SoftMaxHeapSize(JDK-8222145)max heap size of 16 TB (JDK-8221786)
uncommits unused memory (JEP 351)
Java 14
Sources: github.com/nipafx/demo-java-x
(not yet updated)
Records
Simple classes ~> simple code
Spilling Beans
Typical Java Bean:
public class Range {
// part I 😀
private final int low;
private final int high;
public Range(int low, int high) {
this.low = low;
this.high = high;
}
}Spilling Beans
public class Range {
// part II 🙄
public int getLow() {
return low;
}
public int getHigh() {
return high;
}
}Spilling Beans
public class Range {
// part III 🤨
@Override
public boolean equals(Object o) {
if (this == o)
return true;
if (o == null || getClass() != o.getClass())
return false;
Range range = (Range) o;
return low == range.low &&
high == range.high;
}
}Spilling Beans
public class Range {
// part IV 🥴
@Override
public int hashCode() {
return Objects.hash(low, high);
}
}Spilling Beans
public class Range {
// part V 😭
@Override
public String toString() {
return "[" + low + "; " + high + "]";
}
}"Java is Verbose"
Range.java is simple:
declares type
Rangedeclares two components,
lowandhigh
Takes 44 lines!
verbose
room for error
unexpressive
Records
// these are "components"
public record Range(int low, int high) {
// compiler generates:
// * constructor
// * accessors low(), high()
// * equals, hashCode, toString
}Records
The API for a record models the state, the whole state, and nothing but the state.
The deal:
give up encapsulation
couple API to internal state
get API for free
Records
The benefits:
no boilerplate for plain "data carriers"
no room for error
makes Java more expressive
On to the details!
Limited Records
Records are limited classes:
no inheritance
can’t use
extendsare
final
component fields are
finalno additional fields
Customizable Records
Records can be customized:
override constructor
add constructors and
static factory methodsoverride accessors
add other methods
override
Objectmethodsimplement interfaces
Customizable Record
Override constructor:
public Range(int low, int high) {
if (high < low)
throw new IllegalArgumentException();
this.low = low;
this.high = high;
}Customizable Record
Compact form:
// executed before fields are assigned
public Range {
if (high < low)
throw new IllegalArgumentException();
}Summary
use records to replace data carriers
it’s not anty-boilerplate pixie dust
⇝ use only when "the deal" makes sensebeware of limitations
beware of class-building facilites
observe ecosystem for adoption
Pattern Matching
Fewer if-s.
Even More New APIs
Helpful NPEs
Finally can NPEs be helpful!
Typical NPEs
java.lang.NullPointerException
at dev.nipafx.Regular.doing(Regular.java:28)
at dev.nipafx.Business.its(Business.java:20)
at dev.nipafx.Code.thing(Code.java:11)Ok-ish for coders, but suck for everybody else.
Helpful NPEs
With -XX:+ShowCodeDetailsInExceptionMessages:
java.lang.NullPointerException:
Cannot invoke "String.length()" because the return
value of "dev.nipafx.Irregular.doing()"
is null
at dev.nipafx.Regular.doing(Regular.java:28)
at dev.nipafx.Business.its(Business.java:20)
at dev.nipafx.Code.thing(Code.java:11)Why the flag?
The command line option
is needed (for now), because:
performance
security
compatibility
But:
It is intended to enable code details
in exception messages by default
in a later release.
Even More New JVM Features
packaging tool (JEP 343)
Even More Performance
JFR event streaming API (JEP 349)
Shenadoah, G1, ZGC improvements
{kind=link}